任何操作系统都可能使用比计算机的处理器数量更多的进程运行,因此需要一个计划来在进程之间分配处理器的时间。理想情况下,共享对用户进程是透明的。一种常见的方法是为每个进程提供一种错觉,即它有自己的虚拟处理器,并在单个物理处理器上使操作系统复用多个虚拟处理器。本章说明xv6如何在多个进程之间多路复用处理器。
MIT 6.828 Operating System Engineering
Multiplexing
Xv6多路复用方法在两种情况下,会将处理器从一个进程切换到另一个进程。第一种当进程等待设备或管道I/O完成,或等待子进程退出,或在sleep系统调用中等待时,xv6的sleep和wakeup机制会进行切换。第二种,当进程执行用户指令时,xv6会定期强制切换。这种多路复用会造成每个进程都有自己的CPU的错觉,就像xv6使用内存分配器和硬件页表创建每个进程都有自己的内存的错觉一样。
实现多路复用带来了一些挑战。首先,如何从一个进程切换到另一个进程?Xv6使用上下文切换的标准机制;虽然想法很简单,但实现是系统中一些最不透明的代码。其次,如何透明地进行上下文切换?Xv6使用计时器中断处理程序来驱动上下文切换的标准技术。第三,许多CPU可能同时在进程之间切换,并且需要一个锁定计划来避免竞争。第四,当进程退出其内存,并且必须释放其他资源时,它本身无法执行所有这些操作,因为(例如)它无法在使用它的同时释放自己的内核堆栈。Xv6试图尽可能简单地解决这些问题,但结果代码是棘手的(tricky)。
xv6必须为进程之间的协调提供方法。例如,父进程可能需要等待其子进程之一退出,或者读管道的进程可能需要等待其他进程来写管道。Xv6允许进程放弃CPU并sleep去等待事件发生,并允许另一个进程wakeup第一个进程,而不是通过反复检查所需的事件来浪费CPU。需要注意避免导致事件通知丢失的竞争。作为这些问题及其解决方案的一个例子,本章将研究管道的实现。
Code: Context switching
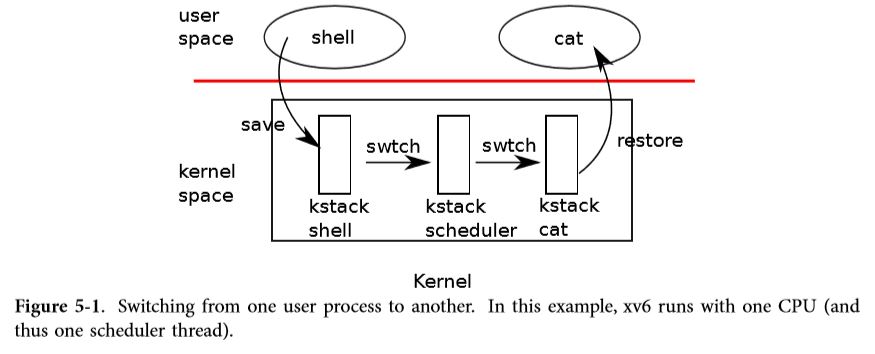 如图5-1所示,要在进程之间切换,xv6在较低的级别上执行两种上下文切换:从进程的内核线程到当前CPU的调度线程,从调度线程到进程的内核线程。xv6永远不会直接从一个用户空间进程切换到另一个用户空间进程;这种情况是通过用户-内核转换(系统调用或中断)、上下文切换到调度程序、上下文切换到新进程的内核线程以及陷阱返回来实现的。在本节中,我们将举例说明在内核线程和调度线程之间切换的机制。
如图5-1所示,要在进程之间切换,xv6在较低的级别上执行两种上下文切换:从进程的内核线程到当前CPU的调度线程,从调度线程到进程的内核线程。xv6永远不会直接从一个用户空间进程切换到另一个用户空间进程;这种情况是通过用户-内核转换(系统调用或中断)、上下文切换到调度程序、上下文切换到新进程的内核线程以及陷阱返回来实现的。在本节中,我们将举例说明在内核线程和调度线程之间切换的机制。
正如我们在第2章中看到的那样,每个xv6进程都有自己的内核堆栈和寄存器集。每个CPU都有一个单独的调度线程,用于在执行调度时使用,而不是任何进程的内核线程。从一个线程切换到另一个线程涉及保存旧线程的CPU寄存器,以及还原以前保存的新线程寄存器;保存并还原%esp和%eip 这意味着CPU将切换堆栈并切换它正在执行的代码。
swtch不直接了解线程;它只是保存和恢复寄存器集,称为上下文。当进程放弃CPU时,进程的内核线程将调用swtch保存自己的上下文并返回到调度程序上下文。每个上下文都由struct context*表示,这是指向存储在所涉及的内核堆栈上的结构的指针。Swtch采用两个参数:struct context **old和struct context *new。它将当前CPU寄存器推送到堆栈上,并将堆栈指针保存在*old。然后swtch将new复制到%esp,弹出以前保存的寄存器,然后返回。
让我们跟随用户进程返回,而不是按照调度程序进入swtch。我们在第3章中看到,每个中断结束时的一种可能性是trap调用yield。Yield调用sched,其调用swtch在proc->context中保存当前上下文,并切换到以前保存在cpu->scheduler(2766)中的调度上下文。
Swtch(2952)首先将其参数从堆栈加载到寄存器%eax和%edx(2959-2960);swtch必须在更改堆栈指针之前执行此操作,并且不能再通过%esp访问参数。然后swtch推送寄存器状态,在当前堆栈上创建上下文。只有callee-save的寄存器需要保存;x86上的约定是,这些寄存器是%ebp、%ebp、%esi、%epp和%esi。Swtch显式推送前四个寄存器(2963-2966);它隐式地将保留最后一个寄存器作为struct context*写入*old。还有一个更重要的寄存器:程序计数器%eip是由调用swtch的call指令保存的,并且在堆栈上就在%ebp之上。保存了旧上下文后,swtch已准备好还原新上下文。它将指向新上下文的指针移动到堆栈指针(2970)中。新堆栈的形式与刚才离开的旧堆栈相同(新堆栈是以前调用swtch时的旧堆栈),因此swtch可以反转序列以还原新的上下文。它弹出%edi、%esi、%ebx和%ebx的值,然后返回(2973-2977)。因为swtch更改了堆栈指针,所以还原的值和返回的指令地址是新上下文中的值。
在我们的示例中,sched调用swtch以切换到cpu->scheduler,即每个cpu调度上下文。调度程序对swtch(2728)的调用保存了该上下文。当我们一直在跟踪返回的swtch时,它并不是返回到sched而是scheduler,它的堆栈指针指向当前CPU的调度程序堆栈,而不是initproc的内核堆栈。
Code: Scheduling
上一节研究了swtch的低级细节;现在让我们以swtch作为给定的,并检查从进程切换到调度程序和返回进程所涉及的约定。想要放弃CPU的进程必须获取进程表锁ptable.lock,释放它所持有的任何其他锁,更新其自己的状态(proc->state),然后调用sched。Yield(2772)遵循这一惯例,sleep和exit也是如此,我们稍后将对此进行研究。Sched再次检查这些条件(2757-2762)并提示这些条件:如果持有锁,CPU运行时要禁用中断。最后,sched调用swtch将当前上下文保存在proc->context中,并切换到cpu->scheduler中的调度器上下文。Swtch在调度程序的堆栈上返回,就像调度程序的swtch返回(2728)一样。调度程序继续for循环,找到要运行的进程,切换到它,并循环重复。
我们刚刚看到,xv6在调用swtch期间持有ptable-lock:swtch的调用方必须已经持有锁,并且对锁的控制传递到可切换到(switched-to)代码。这种惯例是不寻常的锁;典型的约定是获取锁的线程也负责释放锁,这使得对正确性的推理变得更加容易。对于上下文切换,有必要打破典型的约定,因为ptablel.lock保护在swtch中执行时进程状态和上下文字段上不正确的不变量。如果在swtch期间没有持有ptable.lock,则可能会出现一个问题的示例:在yield将其状态设置为RUNNABLE之后,但在swtch导致其停止使用自己的内核堆栈之前,不同的CPU可能会决定运行该进程。结果将是在同一堆栈上运行两个CPU,这不可能是正确的。
内核线程总是以一种方式放弃其处理器,并且总是切换到调度程序中的同一位置,该调度程序(几乎)总是以一种方式切换到一个进程。因此,如果要打印出xv6切换线程的行号,则会观察到以下简单模式:(2728)、(2728)、(2728)、(2728)等。在两个线程之间进行这种程式化切换的过程有时被称为coroutines;在本例中,sched和scheduler是彼此的co-routines。
有一种情况是,调度程序对新进程的swtch最终不会出现分裂。我们在第2章中看到了这种情况:当一个新的进程首次被安排时,它从forkret(2783)开始。Forkret的存在只是为了通过释放pt.lock 来遵守这个惯例;否则,新的过程可能从trapret开始。
调度程序(2708)运行一个简单的循环:找到要运行的进程,运行它,直到它停止,重复。调度程序对其大多数操作都持有ptable.lock,但在其外部循环的每次迭代中都会释放一次锁(并显式启用中断)。这对于此CPU处于空闲状态的特殊情况非常重要(找不到RUNNABLE进程)。如果一个闲置的调度程序循环着连续持有的锁,任何其他运行进程的CPU都不能执行上下文切换或任何与进程相关的系统调用,特别是永远不能将进程标记为RUNNABLE,从而使得闲置CPU脱离调度循环(scheduling loop)。在闲置的CPU上定期启用中断的原因是,由于进程(例如shell)正在等待I/O,因此可能没有RUNNABLE进程;如果调度程序一直禁用中断,I/O将永远无法到达。
调度程序在进程表上循环查找可运行的进程,该进程具有p->state==RUNNABLE。一旦找到一个进程,它就会设置每个CPU当前进程变量proc,用switchuvm切换到进程的页面表,将进程标记为RUNNING,然后调用swtch开始运行它(2722-2728)。
考虑调度代码结构的一种方法是,它安排对每个进程强制执行一组不变量,并在这些不变量不正确时保留ptable->lock。一个不变量的是,如果一个进程是RUNNING,事情必须设置,以便计时器中断的yield可以正确地切换远离该进程;这意味着CPU寄存器必须保存进程的寄存器值(它们实际上不在上下文中),%cr3必须指向进程的页表,%esp必须指向进程的内核堆栈,以便swtch可以正确推入寄存器,并且proc必须指向进程的proc[]插槽。另一个不变因素是,如果进程是RUNNABLE,则必须设置操作,以便空闲CPU的调度程序可以运行它;这意味着p->context必须保存进程的内核线程变量,进程的内核堆栈上没有CPU执行,没有CPU的%cr3引用进程的页面表,并且没有CPU的proc 引用进程。
维护上述不变量是xv6在一个线程中获取ptable.lock(通常在yield中)并在另一个线程中释放锁的原因(调度程序线程或下一个内核线程)。一旦代码开始修改进程的状态为RUNNABLE,它必须保持锁,直到它完成还原不变量:最早的正确释放点是在调度程序停止使用进程的页面表并清除proc 之后。同样,一旦调度程序开始将可运行的进程转换为RUNNING,在内核线程完全运行之前(在swch之后,例如在yield),锁就无法释放。
ptable.lock也保护其他东西:进程ID和空闲进程表插槽的分配,exit和wait之间的相互作用,避免丢失wakeup的机制(见下一节),可能还有其他的东西。也许值得思考的是,为了清晰,也许也是为了性能,ptable.lock的不同功能是否可以拆分。
Sleep and wakeup
调度和锁有助于隐藏一个进程对另一个进程的存在,但到目前为止,我们还没有帮助进程显式交互的抽象。Sleep和wakeup填补了这一空白,让一个进程sleep去等待一个事件,另一个进程在事件发生后将其wakeup。Sleep和wakeup通常被称为序列协调(sequence coordination)或条件同步机制(conditional synchronization),在操作系统文献中还有许多类似机制。
为了说明我们的意思,让我们考虑一个简单的生产者/使用者队列(producer/consumer queue)。此队列类似于将进程中的命令提供给IDE驱动程序的队列(请参阅第3章),但抽象出所有特定于IDE( IDE-specific)的代码。队列允许一个进程向另一个进程发送非零指针。如果只有一个发送方和一个接收方,并且它们在不同的CPU上执行,并且编译器没有过于密集地优化,则此实现将是正确的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21struct q {
void *ptr;
};
void*
send(struct q *q,void *p)
{
while(q->ptr != 0)
;
q->ptr = p;
}
void*
recv(struct q *q)
{
void *p;
while((p = q->ptr) == 0)
;
q->ptr = 0;
return p;
}
Seed循环,直到队列为空(ptr == 0),然后将指针p放入队列中。Recv循环,当队列为非空时,将指针取出。在不同进程中运行时,send和recv都修改了q->ptr,但只在指针为零时send写入指针,而在指针为非零时recv才写入指针,因此不会丢失任何更新。
上面的实现是昂贵的。如果发送方很少发送,接收方将把大部分时间花在希望得到指针的while循环中。如果接收方有一种方法可以放弃(yield)CPU,并且只在send发送指针时才会恢复,则接收方的CPU可以找到更高效的工作。
让我们想象一下一对调用,sleep和wakeup,工作如下。Sleep(chan)休眠在任意值chan上,称为等待通道(wait channel)。Sleep将调用进程置于sleep状态,释放CPU以完成其他工作。Wakeup(chan)wakeup在chan(如果有的话)上睡觉的所有进程,导致它们的Sleep调用返回。如果没有进程在等待 chan,wakeup就什么也做不到。我们可以更改队列实现以使用sleep和wakeup:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void*
send(struct q *q,void *p)
{
while(q->ptr != 0)
;
q->ptr = p;
wakeup(q); /* wake recv */
}
void*
recv(struct q *q)
{
void *p;
while((p = q->ptr) == 0)
sleep(q);
q->ptr = 0;
return p;
}
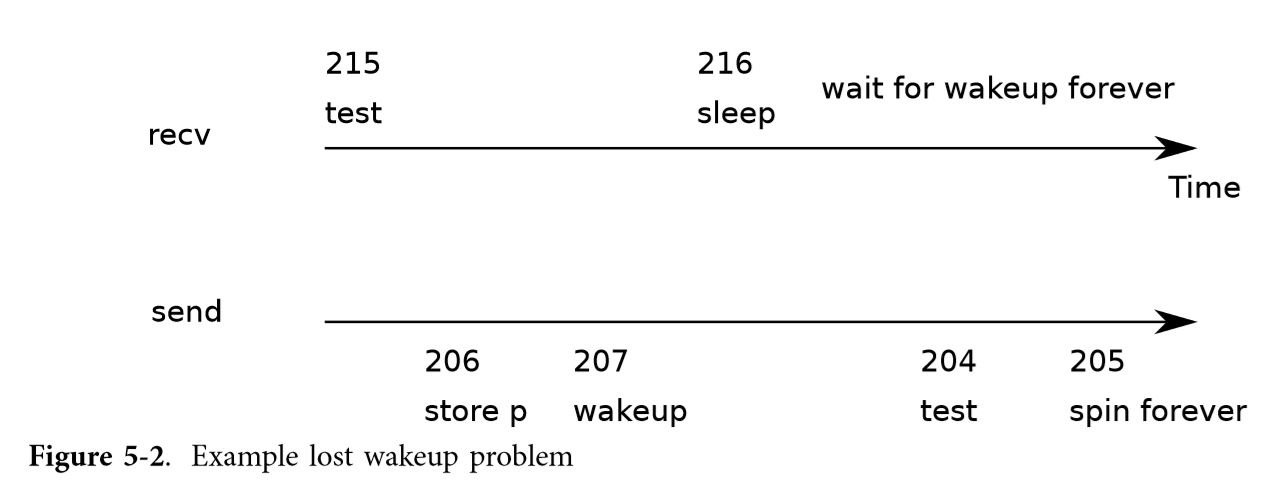 Recv现在放弃CPU而不是旋转(spinning),这很好。然而,事实证明,在不遭受所谓的”lost wake-up”问题的情况下,设计sleep和wakeup接口并不简单(参见图5-2)。假设recv在215行上找到那个
Recv现在放弃CPU而不是旋转(spinning),这很好。然而,事实证明,在不遭受所谓的”lost wake-up”问题的情况下,设计sleep和wakeup接口并不简单(参见图5-2)。假设recv在215行上找到那个q->ptr == 0。recv位于215行和216行时,send在另一个CPU上运行:它将q->ptr更改为非零,并调用wakeup,它不会发现任何进程处于sleep状态,因此不会执行任何操作。现在,recv继续在第216行执行:它调用sleep,然后进入sleep状态。这将导致一个问题:recv正在等待已到达的指针。下一个send将休眠,等待recv使用队列中的指针,此时系统将死锁。
此问题的根源在于,在q->ptr == 0时才会sleep这一不变量在错误的时刻运行的send违反。保护不变量的一种不正确的方法是修改recv的代码,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27struct q {
struct spinlock lock;
void *ptr;
};
void*
send(struct q *q,void *p)
{
acquire(&q->lock);
while(q->ptr != 0)
;
q->ptr = p;
wakeup(q);
release(&q->lock);
}
void*
recv(struct q *q)
{
void *p;
acquire(&q->lock);
while((p = q->ptr) == 0)
sleep(q);
q->ptr = 0;
release(&q->lock);
return p;
}
人们可能希望这个版本的recv能避免lost wakeup,因为锁可以防止在322行和323行之间执行send。它做到了这一点,但它也是死锁:recv持有锁当其在sleep,所以发送者将永远阻塞去等待锁。
我们将通过将锁传递到sleep来修复前面的方案,以便它可以在调用进程被标记为asleep并在sleep通道上等待之后释放锁。锁将强制并发send等待,直到接收者将自己置于sleep状态,这样wakeup就会找到sleep的接收者并将其wakeup。一旦接收者醒来,sleep在返回之前再次获得锁。我们新的正确方案如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27struct q {
struct spinlock lock;
void *ptr;
};
void*
send(struct q *q,void *p)
{
acquire(&q->lock);
while(q->ptr != 0)
;
q->ptr = p;
wakeup(q);
release(&q->lock);
}
void*
recv(struct q *q)
{
void *p;
acquire(&q->lock);
while((p = q->ptr) == 0)
sleep(q,&q->lock);
q->ptr = 0;
release(&q->lock);
return p;
}
Recv持有q->lock的事实阻止send试图在recv检查q->ptr和它的sleep调用之间wakeup它。当然,接收进程必须在sleep时释放q->lock,以便发送方能够将其wakeup。因此,我们希望sleep以原子的方式释放q->lock,并将接收过程置于sleep状态。
完整的sender/receiver实现,当等待接收者使用以前send的值时,也会在send中休眠。
Code: Sleep and wakeup
让我们来看看xv6中sleep和wakeup的实现。基本的想法是让sleep标记当前进程为SLEEPING,然后调用sched释放处理器;wakeup查找在给定的等待通道上休眠的进程,并将其标记为”RUNNABLE”。
sleep(2803)从一些理智检查开始:必须有一个当前进程(2803),sleep必须已通过锁(2808-2809)。然后sleep获得ptable.lock(2818)。现在,要休眠的进程持有ptable.lock和lk两把锁。在调用方中(在示例中,recv)中需要持有lk:它确保了任何其他进程(在示例中,一个正在运行的send)都不能调用wakeup(chan)。现在sleep持有ptable.lock,释放lk是安全的:其他进程可能会调用wakeup(chan),但wakeup不会运行,直到它能够获得ptable.lock,所以它必须等到sleep完成,将进程设为休眠,防止wakeup错过sleep。
有一个小的复杂问题:如果lk等于&ptable.lock,那么sleep当试图获取&ptablek.lock,然后释放lk时,就会死锁。在这种情况下,sleep会考虑获取和释放以相互抵消,并完全跳过它们(2817)。例如,wait(2653)持有&ptablek.lock并调用sleep。
现在,sleep持有ptable.lock,而不是其他人,它可以通过记录sleep通道(sleep channel),改变进程状态,并调用sched(2823-2825),使该进程进入sleep状态。
在某个时候,一个进程会调用wakeup(chan)。wakeup(2864)获取ptablel.lock和调用wakeup 1(其做真正的工作)。重要的是,wakeup持有ptablek.lock既是因为它在操纵进程状态,也是因为,正如我们刚才看到的,ptablek.lock确保sleep和wakeup不会相互错过。Wakeup1是一个单独的函数,因为有时调度程序需要执行wakeup,当它已经持有ptablek.lock;稍后我们将看到这方面的一个示例。Wakeu1(2853)在进程表上循环。当它发现一个进程处于具有匹配chan的状态时,它会将该进程的状态更改为RUNNABLE。下次运行调度程序时,它将看到进程已准备好运行。
在任何唤醒条件下,都必须在持有锁的时候调用wakeup;在上面的示例中,锁是q->lock。为什么sleep进程不会错过wakeup的完整论据是,在任何时候,从它检查条件之前,直到它处于sleep状态,它持有条件锁(the lock on the condition)或ptablel.lock或两者兼而有之。由于wakeup是在持有这两个锁的情况下执行的,因此wakeup必须在潜在的sleeper检查条件之前执行,或者在潜在的sleeper完成将自己置于sleep状态之后执行。
有时,多个进程在同一通道上休眠;例如,多个进程试图从管道中读取。一个简单调用就会把他们都唤醒。其中一个将首先运行,并获得调用sleep的锁,并(在管道的情况下)读取管道中等待的任何数据。其他进程会发现,尽管被wakeup,但没有数据可以读取。从他们的角度来看,这种wakeup是”虚假的”(spurious),他们必须再次休眠。因此,sleep总是在检查条件的循环中被调用。
sleep和wakeup的调用者可以使用任何相互方便的号码作为通道;实际上,xv6通常使用等待中涉及的内核数据结构的地址,如磁盘缓冲区。如果sleep/wakeup的两种使用不小心选择了相同的通道,则不会造成任何伤害:它们会看到虚假(spurious)的wakeup,但如上所述的循环会容忍此问题。sleep/wakeup的魅力在于它既轻量级(不需要创建特殊的数据结构作为sleep通道),并提供了间接层(调用者不需要知道他们正在与什么特定的进程交互)。
Code: Pipes
我们在本章前面使用的简单队列是一个玩具,但xv6包含两个真正的队列,它们使用sleep和wakeup来同步读者和写者。一种是在IDE驱动程序中:进程将磁盘请求添加到队列中,然后调用sleep。中断处理程序使用wakeup来提醒进程其请求已完成。
一个更复杂的例子是管道的实现。我们在第0章中看到了管道的接口:写入管道一端的字节被复制到内核内部的缓冲区中,然后可以从管道的另一端读出。接下来的章节将检查围绕管道的文件系统支持,但现在让我们来看看pipewrite和piperead的实现。
每个管道都由一个结构pipe表示,其中包含一个lock和一个data缓冲区。字段nread和nread计数从缓冲区读取和写入缓冲区的字节数。缓冲区是环绕的:buf[PIPESIZE-1]后写入的下一个字节是buf[0],但计数不会环绕。此约定允许实现区分完整缓冲区(nwrite == nwrite + PIPESIZE)和空缓冲区(nwrite == nread),但这意味着索引到缓冲区中必须使用buf[nwrite%PIPESIZE],而不仅仅是buf[nread](类似地用于nwrite)。假设对piperead和pipewrite的调用在两个不同的CPU上同时发生。
Pipewrite(6530)从获取管道锁开始,其保护计数、数据及其关联的不变量。Piperead(6551)然后也尝试获取锁,但不能。它在acquire(1574)自旋等待锁。在piperead等待时,管道写入循环在被written—addr[0]、addr[1]、…、addr[n-1]上循环-依次将每个字节添加到管道中(6544)。在此循环中,可能会发生缓冲区溢出(6536)。在这种情况下,pipewrite调用wakeup去提醒任何处于sleep状态的读取者注意到有数据在缓冲区中等待,然后在&p->nwrite上休眠,等待读取者从缓冲区中取出一些字节。sleep释放p->lock,作为使pipewrite进程进入sleep状态的一部分。
现在,p->lock可用了,piperead设法获得了它,并开始认真地运行:它发现p->nread != p->nwrite(6556)(pipewrite进入sleep状态,因为p->nwrite == p->nread+PIPESIZE(6536)),因此它陷入for循环,将数据复制出管道(6563-6567),并按复制的字节数增加nread。现在有许多字节可用于写入,因此piperead调用wakeup(6568),在它返回给调用方之前w唤醒任何处于sleep状态的写入这。wakeup发现一个进程正在&p->nwrite上休眠,这个进程正在运行pipewrite,但在缓冲区溢出时停止。它将该过程标记为RUNNABLE。
管道代码为读取者和写入者使用单独的sleep通道(p->nread 和p->write);这可能会使系统在不可能出现的情况下更有效率,因为有大量的读者和写者在等待相同的管道。管道代码休眠在检查sleep条件的循环中;如果有多个读者或写者,除了第一个醒来的过程外,其他人都会看到条件仍然是假的,然后再休眠。
Code: Wait,exit,and kill
sleep和wakeup可用于多种等待。看到第0章的一个有趣的示例是父进程用来等待子进程退出的wait系统调用。在xv6中,当子进程退出时,它不会立即死亡。相反,它切换到ZOMBIE进程状态,直到父进程调用wait去退出。然后,父进程负责释放与进程相关的内存,并准备结构proc进行重用。如果父进程在子进程之前退出,则init进程领养子进程并等待它,以便每个子进程之后都有一个父进程进行清理。请记住父进程和子进程之间wait和exit之间的竞争的可能性,以及exit和exit之间的竞争可能性。
wait从获取ptable.lock开始。然后,它扫描进程表,查找子进程。如果wait发现当前进程有子进程,但没有一个已退出,它调用sleep等待其中一个退出(2689),然后再次扫描。在这里,在sleep中释放的锁是ptable.lock,我们上面看到的特殊情况。
Exit获取ptable.lock,然后唤醒在与当前进程的父进程proc(2628)相等的等待通道上休眠的任何进程;如果有这样的过程,将是wait中的父进程。这看起来可能不成熟(premature),因为exit还没有将当前进程标记为ZOMBIE,但它是安全的:尽管wakeup可能会将父进程标记为RUNNABLE,但wait中的循环无法运行,直到exit通过调用sched进入调度程序中释放ptable.lock,因此wai只有在exi将退出进程的状态设置为ZOMBIE(2640)之后才能查找退出进程。在exit重新安排之前(reschedules),它将当前退出进程的子进程重新抚养,并将他们传给initproc(2630-2637)。最后,exit调用sched去放弃(relinquish)CPU。
如果父进程处于等待状态,调度程序最终将运行它。对sleep的调用返回时持有ptable.lock;wait重新扫描进程表,并找到state == ZOMBIE 的退出子进程(2666)。它记录子进程的pid,然后清理struct proc,释放与该进程相关的内存(2668-2676)。
子进程可以在exit过程中完成大部分清理工作,但重要的是父进程是释放p->kstack和p->pgdir的进程:当子进程运行exit时,它的堆栈位于分配为p->kstack的内存中,并且它使用自己的页表。只有在子进程最后一次完成运行后,才能通过调用swtch(通过sched)释放它们。这也是调度程序在其自己的堆栈上运行而不是在调用sched的线程堆栈上运行的原因之一。
虽然exit允许进程自行终止,但kill(2875)允许一个进程终止另一个进程。如果直接杀死受害者进程(destroy the victim process),kill将会过于复杂,因为受害者进程可能在另一个CPU上执行或在更新内核数据结构的中途处于sleep状态。为了应对这些挑战,kill只做了一点点:它只设置了受害者的p->killed,如果它处在休眠状态,就会唤醒他。最终,受害者将进入或离开内核,此时,如果设置了p->killed,trap中的代码将调用exit。如果受害者在用户空间中运行,它很快就会通过进行系统调用或由于计时器(或其他一些设备)中断而进入内核。
如果受害者过程处于sleep状态,wakeup的调用会导致受害者进程从sleep中返回。这是潜在的危险,因为正在等待的条件可能不正确。但是,xv6的sleep调用总是被包装在一个while循环中,该循环会在sleep返回后重新测试该条件。一些sleep调用也会在循环中测试p->killed,如果设置了p->killed,则放弃该活动。只有在这种放弃是正确的情况下,才会这样做。例如,如果设置了killed的标志,则管道读和写代码(6537)返回。最终代码将返回到trap,这将再次检查标志并退出。
一些xv6的sleep循环不会检查p->killed,因为代码位于应该是原子的多步骤系统调用的中间。IDE驱动程序(4279)就是一个示例:它不检查p->killed,因为磁盘操作可能是一组写入操作之一,这些写入操作都是文件系统保持在正确状态所必需的。为了避免部分操作后清理工作的复杂性,xv6将IDE驱动程序中的进程的终止延迟到稍后更容易终止该进程(例如,当整个文件系统操作已完成且进程大概率要返回到用户空间)。
Real world
Xv6调度程序实现了一个简单的调度策略,该策略依次运行每个进程。此策略称为round robin(轮询调度)。实际操作系统实施更复杂的策略,例如,允许进程具有优先级。其想法是,调度程序将优先运行高优先级进程,而不是运行低优先级线程。这些策略可能很快变得复杂,因为通常存在相互竞争的目标:例如,操作可能也希望保证公平性和高吞吐量。此外,复杂的策略可能导致意想不到的互动,如优先倒置(priority inversion)和车队(convoys)。当低优先级和高优先级进程共享锁时,可能会发生优先级反转,即当低优先级进程获取锁时,可能会导致高优先级进程不运行。当许多高优先级的进程正在等待获得共享锁的低优先进程时,可以形成一个长车队;一旦车队组成,他们可以坚持很久时间。为了避免这类问题,在复杂的调度程序中需要额外的机制。
sleep和wakeup是一种简单有效的同步方法,但还有很多其他方法。所有这些问题的第一个挑战是避免我们在本章开头看到的”missed wakeups”问题。原来的Unix内核的sleep只是禁用中断,这就足以,因为Unix运行在单CPU系统上。由于xv6在多处理器上运行,因此它将显式锁定添加到sleep中。FreeBSD的msleep也采取了同样的方法。Plan’s 9的sleep使用回调函数(callback function),该函数在sleep前使用调度锁运行;该功能作为sleep状态的最后一分钟检查,以避免missed wakeups。Linux内核的sleep使用显式进程队列,而不是等待通道;队列有自己的内部锁。
在wakeup中扫描具有匹配chan整个进程列表效率低下。更好的解决方案是用一个数据结构来取代sleep和wakeup中的chan,该数据结构包含在该结构上休眠的进程列表。Plan’s 9的sleep和wakeup将这种数据结构称为rendezvous point或Rendez。许多线程库将相同的结构称为条件变量(condition variable);在这种情况下,操作sleep和wakeup被称为wait和signal。所有这些机制都有相同的味道:sleep条件是由某种锁定在sleep过程中原子下降保护。
wakeup的实现唤醒了在特定通道上等待的所有进程,并且可能存在许多进程正在等待该特定通道的情况。操作系统将安排所有这些进程,他们将争先恐后地检查sleep状态。以这种方式运行的进程有时被称为雷鸣般的羊群(thundering herd),这最好避免。大多数条件变量都有两个wakeup的原语(primitives):信号(signal),它唤醒一个进程,广播(broadcast),它唤醒等待的所有进程。
信号量(Semaphores)是另一种常见的协调机制。信号量是一个整数值,具有两个运算,递增和递减(或上下)。总是可以增加信号量,但信号量值不允许下降到零以下:零信号量的递增将休眠,直到另一个进程递增信号量,然后这两个操作取消(cancel out)。整数值通常对应于实际计数,例如管道缓冲区中可用的字节数或进程所具有的僵死子进程。使用显式计数作为抽象的一部分可以避免”missed wakeup”问题:有一个记录已发生的wakeup的数量的显式计数。计数值还避免了虚假的wakeup和雷鸣般的羊群(thundering herd)问题。
终止进程并对其进行清理会给xv6带来很大的复杂性。在大多数操作系统中,它更加复杂,因为受害者进程可能在内核深处休眠,并且展开(unwinding)其堆栈需要非常仔细的编程。许多操作系统使用显式机制(如longjmp)来展开堆栈。此外,还有其他事件可能会导致休眠进程被唤醒,即使它正在等待的事件还没有发生。例如,当进程处于休眠状态时,另一个进程可能会向其发送信号。在这种情况下,进程将从中断的系统调用返回,其值为-1,错误代码设置为EINTR。应用程序可以检查这些值并决定要执行的操作。Xv6不支持信号,这种复杂性也不会出现。
Xv6对kill的支持并不完全令人满意:有一些sleep循环可能应该检查p->killed。一个相关的问题是,即使是检查p->killed的sleep循环,sleep和kill之间也有竞争;后者可能会设置p->killed,并试图在受害者的循环检查p->killed之前,但在它调用sleep之前唤醒受害者。如果出现此问题,则在等待情况发生之前,受害者不会注意到p->killed。这可能会稍晚(例如,当IDE驱动程序返回受害者正在等待的磁盘块时)或永远不会(例如,如果受害者正在从控制台的输入中等待,但用户不键入任何输入)。
Exercises
- Sleep has to check lk != &ptable.lock to avoid a deadlock (2817-2820). It could eliminate the special case by replacing
if(lk != &ptable.lock){ acquire(&ptable.lock); release(lk); }
with
release(lk); acquire(&ptable.lock);
Doing this would break sleep. How? - Most process cleanup could be done by either exit or wait,but we saw above that exit must not free p->stack. It turns out that exit must be the one to close the open files. Why? The answer involves pipes.
- Implement semaphores in xv6. You can use mutexes but do not use sleep and wakeup. Replace the uses of sleep and wakeup in xv6 with semaphores. Judge the re
- Fix the race mentioned above between kill and sleep,so that a kill that occurs after the victim’s sleep loop checks p->killed but before it calls sleep results in the victim abandoning the current system call.
- Design a plan so that every sleep loop checks p->killed so that,for example,a process that is in the IDE driver can return quickly from the while loop if another kills that process.