Xv6在多处理器上运行,多核CPU的计算机独立执行代码。这些多核CPU在单个物理地址空间上运行,并共享数据结构;xv6必须引入一个协调机制,以防止它们相互干扰。即使在单处理器上,xv6也必须使用某种机制来防止中断处理程序干扰非中断代码。Xv6对两者都使用相同的低级概念:锁。锁提供互斥,确保一次只能有一个CPU拥有锁。如果xv6仅访问数据结构,同时持有特定的锁,则xv6可以确保一次只有一个CPU访问数据结构。在此情况下,我们说锁保护了数据结构。
MIT 6.828 Operating System Engineering
本章的其余部分解释了为什么xv6需要锁,xv6是如何实现锁的,以及它是如何使用锁的。一个关键的观察是,如果你看xv6中的一行代码,你必须问自己,是否有另一个处理器可以改变该行的预期行为(例如,因为另一个处理器也在执行该行或另一行代码去修改共享变量),以及如果中断处理程序运行时会发生什么情况。在这两种情况下,您必须记住,一个C语句可以是多条机器指令,因此另一个处理器或中断可能会在C语句的中间出现。不能假定页面上的代码行是按顺序执行的,也不能假定单个C语句将以原子方式执行。并发使得对正确性的推理变得更加困难。
Race condition
作为为什么我们需要锁的示例,请考虑共享单个磁盘的多个处理器,例如xv6中的IDE磁盘。磁盘驱动程序维护重要的磁盘请求(4121)的链表,处理器可以同时向列表中添加新请求(4254)。如果没有并发请求,则可以向下面这样实现链表:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct list {
int data;
struct list *next;
};
struct list *list = 0;
void
insert(int data)
{
struct list *l;
l = malloc(sizeof *l);
l->data = data;
l->next = list;
list = l;
}
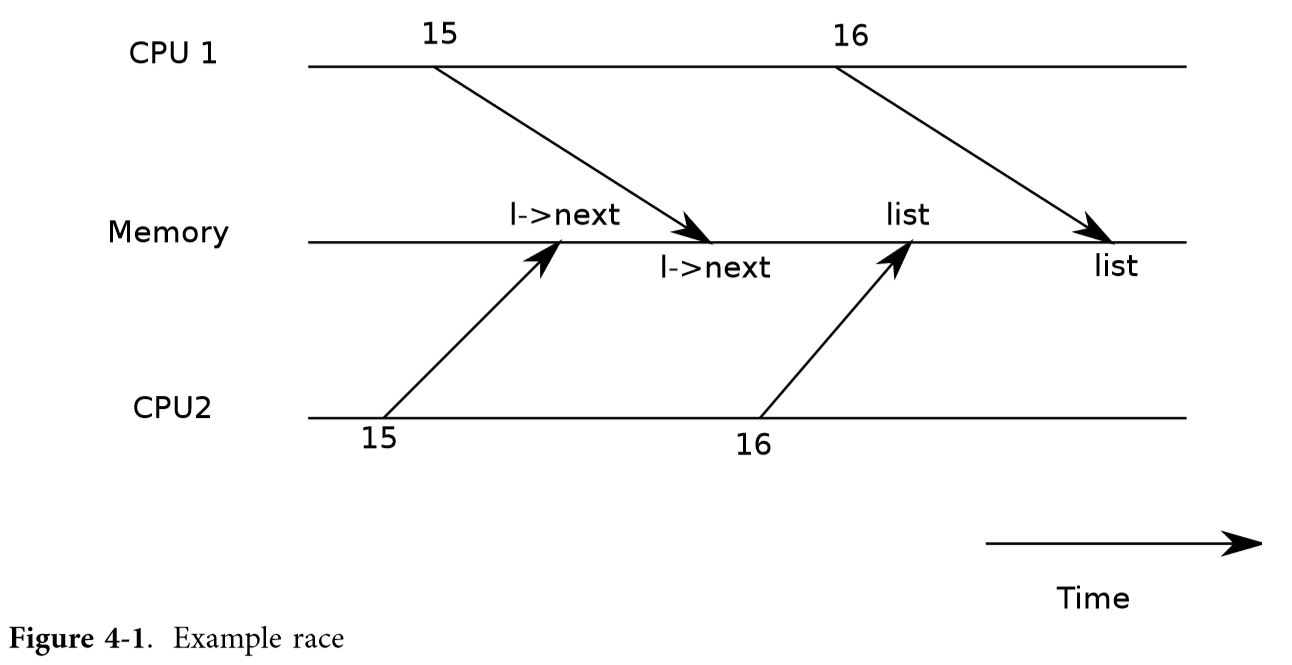
证明此实现正确是数据结构和算法类中的典型练习。尽管这种实现可以被证明是正确的,但它不是正确的,至少在多处理器上不是。如果两个不同的CPU同时执行insert,则可能会在执行16之前执行第15行(参见图4-1)。如果发生这种情况,现在将有两个列表节点,每个节点的node设置为list的前一个值。当list的两个赋值发生在第16行时,第二个分配将覆盖第一个分配;第一个分配中涉及的节点将丢失。这种问题被称为race condition。race的问题在于,它们取决于所涉及的两个CPU的确切时间,以及它们的内存操作是如何由内存系统排序的,因此很难重现。例如,在调试插入时添加打印语句可能会更改执行的时间,从而使竞争消失。
避免race的典型方法是使用锁。锁确保相互排斥(mutual exclusion),因此一次只能执行一个 CPU的Insert;这使得上面的场景是不可能的。上述代码的正确锁定版本只添加几行(未编号):1
2
3
4
5
6
7
8
9
10
11
12
13
14struct list *list = 0;
struct lock listlock;
void
insert(int data)
{
struct list *l;
acquire(&listlock);
l = malloc(sizeof *l);
l->data = data;
l->next = list;
list = l;
release(&listlock);
}
当我们说锁保护数据时,我们实际上意味着锁保护一些适用于数据的不变量(invariants)集合。不变量是在操作时维护的数据结构的属性。通常,操作的正确行为取决于操作开始时的不变量是否为true。该操作可能会暂时违反(violate)不变量,但必须在完成之前重新建立它们。例如,在链表中,不变量是列表中第一个节点上的节点,以及每个节点的next字段指向的下一个节点。Insert的实现暂时违反了这一不变量:第13行创建了一个新的列表元素l,目的是使l是列表中的第一个节点,但l的next指针尚未指向列表中的下一个节点(在第15行重新建立),并且list还没有指向l(重新建立在第16行)。我们上面检查的race condition之所以发生,是因为第二个CPU执行的代码依赖于列表不变量,而这些代码暂时破坏了不变量。正确使用锁可确保一次只能有一个CPU对数据结构进行操作,因此,当没有持有数据结构的不变量,CPU不会执行数据结构操作。
Code: Locks
Xv6把锁表示为struct spinlock(1501,自旋锁)。结构中的关键字段是locked,当锁可用时,该字为零,在持有时为非零。从逻辑上讲,xv6应该通过执行代码来获取锁,如1
2
3
4
5
6
7
8
9
10void
acquire(struct spinlock *lk)
{
for(;;) {
if(!lk->locked) {
lk->locked = 1;
break;
}
}
}
遗憾的是,此实现不能保证在现代多处理器上相互排斥。可能会发生两个(或更多)CPU同时到达第25行,看到 lk->locked为零,然后通过执行第26行和第27行抓住锁。此时,两个不同的CPU持有锁,这违反了相互排除的属性。acquire的这种实现并没有帮助我们避免race condition,而是有自己的race condition。这里的问题是第25行和第26行作为单独的操作执行。为了使上述例程正确,第25行和第26行必须在一个原子(即不可分割)步骤中执行。
要以原子方式执行这两行,xv6依赖于特殊的386硬件指令xchg(0569)。在一个原子操作中,xchg将内存中的字与寄存器的内容交换。函数acquire(1574)在循环中重复此xchg指令;每次迭代读取lk->locked,并以原子方式将其设置为1(1583)。如果锁被持有,lk->locked将已经是 1,因此xchg返回1,循环继续。但是,如果xchg返回0,则acquire已成功获取锁,之前locked为0,现在则为1,因此循环可以停止。一旦获取锁,为了用于调试,acquire会记录获取锁的CPU和堆栈跟踪。当一个进程获取锁而忘记释放它时,这些信息可以帮助识别罪魁祸首。这些调试字段受锁保护,只能在持有锁的情况下进行编辑。
函数release(1602)与acquire相反: 它清除调试字段,然后释放锁。
Modularity and recursive locks
系统设计追求干净的模块化抽象:调用方不需要知道被调用方如何实现特定功能。锁的接口会干扰此模块化。例如,如果CPU持有特定的锁,它就不能调用任何试图重新获取该锁的函数f:因为调用方在f返回之前无法释放锁,因此,如果f尝试获取相同的锁,它将永远自旋或死锁。
没有透明的解决方案允许调用方和被调用方隐藏他们使用的锁。一个常见的、透明但不能令人满意的解决方案是递归锁,它允许被调用方重新获取其调用方已经持有的锁。此解决方案的问题在于,递归锁不能用于保护不变量。在上面insert调用acquire(&listlock)之后,它可以假定没有其他函数持有锁,没有其他函数在列表操作的中间,最重要的是持有所有列表不变量。在具有递归锁的系统中,insert在调用acquire后不能保证任何内容:也许acquire成功只是因为insert的一个调用方已经持有锁,并且正在编辑列表数据结构。他们可能只有不变量,也可能没有。该列表不再保护它们。锁对于保护调用者和被调用者之间的隔离与保护不同CPU之间的隔离同样重要;递归锁则放弃了这个性质。
由于没有理想的透明解决方案,我们必须考虑锁作为函数规范的一部分。程序员必须安排该函数在持有f所需的锁的同时不调用函数f。Locks强制程序员进入我们定义的抽象中。
Code: Using locks
Xv6小心使用锁来编程,以避免出现race conditions。一个简单的示例是IDE driver(4100)。如本章开头所述,iderw(4254))有一个磁盘请求队列,处理器可以同时向列表中添加新的请求(4254)。为了保护此列表和驱动程序中的其他不变量,iderw要acquire idelock(4265)并在函数结束时release。练习1探讨如何触发我们在本章开头看到的竞争条件,方法是将acquire移动到队列操作之后。尝试这个练习是值得的,因为它将明确触发race并不那么容易,这表明很难找到race-conditions的BUG。xv6依旧可能存在一些races。
使用锁的一个困难部分是决定要使用多少锁,以及每个锁保护哪些数据和不变量。这里有一些基本原则。首先,当一个CPU可以在另一个CPU可以读取或写入变量的同时编写这个变量时,都应引入一个锁,以防止这两个操作重叠。其次,请记住锁保护不变量:如果不变量涉及多个数据结构,则通常所有结构都需要由单个锁保护,以确保保持不变量。
上面的规则说明锁何时必要,但对锁何时不必要什么都不说,为了提高效率,重要的是不要锁定太多,因为锁减少了并行性。如果效率并不重要,那么人们可以使用单处理器计算机,根本不用担心锁。为了保护内核数据结构,只需创建一个在进入内核时必须获取并在退出内核时释放的锁就足够了。许多单处理器操作系统已被转换为在多处理器上运行使用这种方法,有时被称为”巨大的内核锁”,但该方法牺牲了真正的并发性:一次只能有一个CPU在内核中执行。如果内核执行任何繁重的计算,则使用更大的一组更细粒度的锁将更有效,以便内核可以同时在多个CPU上执行。
最终,锁粒度的选择是并行编程中的一项练习。Xv6使用一些粗糙的数据结构特定的锁;例如,xv6使用单个锁保护进程表及其不变量,如第5章所述。更精细的方法是在进程表中对每个条目都有一个锁,以便在进程表中处理不同条目的线程可以并行进行。但是,它使在整个进程表上具有不变的操作复杂化,因为它们可能必须取出多个锁。希望xv6的示例将有助于传达如何使用锁。
Lock ordering
如果通过内核的代码路径必须获得多个锁,则所有代码路径都必须以相同的顺序获取锁,这一点很重要。如果他们不这样做,就有陷入死锁的危险。假设xv6中的两个代码路径需要锁A和B,但代码路径1按顺序A和B获取锁,而其他代码按顺序B和A获取锁。这种情况可能会导致死锁,因为代码路径1可能会获取锁A,在它获取锁B之前,代码路径2可能会获取锁B。现在这两个代码路径都不能继续,因为代码路径1需要锁定B,而B现在由代码2持有,代码路径2需要锁定A,但其由代码路径1持有A。为了避免这种死锁,所有代码路径都必须以相同的顺序获取锁。避免死锁说明了锁必须是函数规范(function’s specification)的一部分:调用方必须以一致的顺序调用函数,以便函数以相同的顺序获取锁。
因为xv6使用粗粒度的锁,xv6很简单,所以xv6几乎没有锁序链(lock-order chains)。最长的链子只有两层深(two deep)。例如,ideintr在调用wakeup时持有ide锁,wakeup则需要获取ptable锁。还有很多其他涉及sleep和wakeup的例子。这些命令的产生是因为sleep和wakeup有一个复杂的不变量,如第5章所述。在文件系统中有许多两个链的示例,因为文件系统必须获取目录上的锁和该目录中文件上的锁,才能正确地从其父目录中取消文件的链接。Xv6总是按顺序获取锁的第一个父目录,然后是文件。
Interrupt handlers
Xv6使用锁保护在一个CPU上运行的中断处理程序不受访问另一个CPU上相同数据的非中断代码的影响。例如,计时器中断处理程序(3364)会增加ticks,但另一个CPU可能同时处于sys_sleep状态,也使用相同变量(3723)。锁tickslock同步两个CPU对单个变量的访问。
中断甚至在单个处理器上也会导致并发:如果启用了中断,则可以随时停止内核代码以运行中断处理程序。假设iderw拿着idelock,然后被中断去运行ideintr。Ideintr会试图锁定idelock,看到它被持有,并等待它被释放。在这种情况下,idelock永远不会被释放–只有iderw才能释放它,而且在ideintr返回之前,iderw不会继续运行–因此处理器,最终整个系统将死锁。
若要避免这种情况,如果中断处理程序使用锁,处理器绝不能在启用中断的情况下持有该锁。Xv6更为保守:在启用中断时,它从不持有任何锁。它使用pushcli(1655)和popcli(1665)来管理堆栈的”禁用中断”操作(cli是x86的禁用中断指令)。在尝试获取锁(1576)之前Acquire调用pushcli,并在释放锁(1621)后release调用popcli。Pushcli(1655)和popcli(1666)不仅仅是cli和sti的包装:,函数内存还存在计数器,因此需要两个调用popcli才能撤销两次调用pushcli;这样,如果代码获取两个不同的锁,中断将不会重新启用,直到两个锁都被释放。
在xchg可能获得锁之前让acquire去调用pushcli很重要。如果交换两者位置,则在启用中断的情况下持有锁在几个指令周期之后,不幸的定时中断就会使系统死锁。同样,只有在xchg释放锁(1583)之后,release才调用popcli也很重要。
中断处理程序和非中断代码之间的交互提供了一个很好的示例,说明了递归锁存在问题的原因。如果xv6使用递归锁(如果第一次获取也发生在CPU上,则允许在CPU上进行第二次获取),则中断处理程序可以在非中断代码处于关键部分时运行。这可能会造成严重破坏,因为当中断处理程序运行时,处理程序所依赖的不变量可能会被暂时违反。例如,ideintr(4202)假定具有未完成请求的链表格式正确。如果xv6使用递归锁,则ideintr可能会在idew正在操作链接列表时运行,并且链表最终将处于不正确的状态。
Memory ordering
本章假定处理器按照它们在程序中出现的顺序启动和完成指令。但是,许多处理器执行指令的顺序不正常,以实现更高的性能。如果指令需要多个周期才能完成,处理器可能希望提前发出指令,以便它可以与其他指令重叠并避免处理器停滞。例如,处理器可能会注意到,在指令A和B的串行序列中,A和B并不相互依赖,并在A之前启动指令B,以便在处理器完成A时完成指令B,但是并发性可能会将这种重新排序暴露给软件,这将导致不正确的行为。
例如,人们可能想知道,如果release只是将0分配给lk->locked,而不是使用xchg,会发生什么情况。这个问题的答案不清楚,因为不同代的x86处理器对内存排序做出了不同的保证。如果lk->locked=0,允许在popcli之后重新排序,则acquire可能会中断,因为在释放锁之前将启用另一个线程中断。为了避免依赖不明确的处理器规格有关内存排序,xv6不承担任何风险,并使用xchg,即处理器必须保证不重新排序。
Real world
并发原语和并行编程是研究的活跃领域,因为使用锁编程仍然具有挑战性。最好使用锁作为较高级别的构造(如同步队列)的基础,尽管xv6并不这样做。如果您使用锁编程,则明智的做法是使用尝试识别竞争条件的工具,因为很容易错过需要锁的不变量。
用户级程序也需要锁,但在xv6应用程序中只有一个执行线程,进程不共享内存,因此xv6应用程序中不需要锁。
可以在没有原子指令的情况下实现锁,但成本很高,大多数操作系统都使用原子指令。
当锁满足时,原子指令也不是免费的。如果一个处理器在其本地缓存中缓存了一个锁,而另一个处理器必须获取锁,则更新持有锁的行的原子指令必须将该行从一个处理器的缓存移动到另一个处理器的缓存中,然后可能使其失效缓存行的任何其他副本。从另一个处理器的缓存中获取缓存行的成本可能比从本地缓存中获取一行的成本要高出数级。
为了避免与锁相关的开销,许多操作系统使用无锁定数据结构和算法,并尝试避免这些算法中的原子操作。例如,可以实现一个链表,如本章开头的链表,在列表搜索过程中不需要锁定,以及只需要一个原子指令在链表中插入项。
Exercises
- Remove the xchg in acquire. explain what happens when you run xv6?
- Move the acquire in iderw to before sleep. is there a race? why don’t you observe it when booting xv6 and run stressfs? increase critical section with a dummy loop; what do you see now? explain.
- Setting a bit in a buffer’s flags is not an atomic operation: the processor makes a copy of flags in a register,edits the register,and writes it back. Thus it is important that two processes are not writing to flags at the same time. xv6 edits the B_BUSY bit only while holding buflock but edits the B_VALID and B_WRITE flags without holding any locks. Why is this safe?