MIT 6.828 Operating System Engineering
操作系统的一个关键要求是支持多个活动。例如,使用第0章中描述的系统调用接口,进程可以使用fork创建进程。操作系统必须安排这些进程可以共享(time-share)计算机的资源。例如,进程可能比计算机中的处理器启动更多的新进程,但所有进程都必须能够取得一些进展。此外,操作系统必须安排进程之间的隔离。也就是说,如果一个进程有一个bug并出现错误,它不应该影响不依赖于失败进程的进程。然而,完全隔离要求太严格(strong),因为进程应该有可能相互作用。例如,用户可以方便地组合进程来执行复杂的任务(例如,通过使用管道)。因此,操作系统的实现必须满足三个要求: 多路复用、隔离和交互。
本章概述了如何组织操作系统以实现上述3个要求。事实证明,这样做的方法有很多,但本文重点围绕一个整体内核(monolithic kernel),介绍在许多Unix操作系统都使用的主流设计。本章通过跟踪xv6开始运行时创建的第一个进程来说明此组织。在此过程中,我们将研究xv6提供的所有主要抽象的实现、它们如何交互以及如何满足多路复用、隔离和交互的三个要求。大多数xv6为了避免第一个进程的特殊性,重用xv6提供的标准操作的代码。后面的章节将更详细地探讨每个抽象。
Xv6在PC平台上的英特尔80386或更高版本(”x86”) 处理器上运行,其大部分低级功能(例如,进程实现) 都是特定于x86的。本书假定读者已经在一些体系结构上做了一些机器级的编程,并将在提出x86特定的想法时引入它们。附录A简要概述了PC平台。
物理资源抽象
当遇到操作系统时,人们可能会问的第一个问题是,为什么会有它?也就是说,可以将图0-2中的系统调用实现为一个库,应用程序将使用该库进行链接。在这个计划中,每个应用程序甚至可以有自己的库,也许是根据自己的需要量身定做的。同时,应用程序可以直接与硬件资源交互,并以应用程序的最佳方式使用这些资源(例如,实现高性能或可预测的性能)。嵌入式设备或实时系统的一些微小操作系统就是这样组织的。
这种方法的缺点是应用程序可以自由使用库,这意味着它们也可以不使用它。如果他们不使用操作系统库,则操作系统无法强制进行时间共享。它必须依赖于应用程序才能正常运行,例如,定期放弃处理器,以便另一个应用程序可以运行。对于一个所有应用程序都彼此信任的系统来说,这样的合作分时方案也许是可以的,但如果应用程序相互不信任,这将不会提供强大的隔离。
要实现强隔离,一个有用的方法是不允许应用程序直接访问硬件资源,而是将资源抽象为服务。例如,应用程序仅通过open read write close系统调用与文件系统交互,而不是读取和写入原始磁盘扇区。这为应用程序提供了路径名的便利性,并允许操作系统(作为接口的实现者) 管理磁盘。
类似地,在Unix中应用程序通过fork作为进程运行,允许操作系统在不同进程之间切换时代表应用程序保存和还原寄存器,这样应用程序就不必知道进程切换。此外,如果应用程序是一个无限循环,它允许操作系统强制切换出占用处理器的应用程序。
另一个例子是,Unix进程使用exec来构建它们的内存映像,而不是直接与物理内存交互。这使操作系统能够决定将进程放置在内存中的位置,并在内存不足的情况下移动数据,并为应用程序提供了文件系统存储其映像的便利。
为了支持控制应用程序之间的交互,Unix应用程序只能使用文件描述符,而不是自己的一些共享约定(例如,保留一段物理内存)。Unix文件描述符抽象出所有共享细节,在与终端、文件系统或管道发生交互时,会向应用程序隐藏,但允许操作系统控制交互。例如,如果一个应用程序出现故障,它可以关闭通信通道。
正如您所看到的,图0-2中的系统调用接口经过精心设计,为程序员提供了便利的同时,也为强制隔离接口的实现提供便利。Unix接口并不是抽象资源的唯一方法,但事实证明它是一种非常好的方法。
用户模式、内核模式和系统调用
为了在使用系统调用的软件和实现系统调用的软件之间提供强大的隔离,我们需要应用程序和操作系统之间的硬边界。如果应用程序出错,我们不希望操作系统失败。相反,操作系统应该能够清理应用程序并继续运行其他应用程序。这种强大的隔离意味着应用程序不应该能够写入操作系统维护的数据结构,不应该能够覆盖操作系统的指令等。
为提供这种强隔离处理器提供硬件支持。 例如,与许多其他处理器一样,x86处理器有两种处理器执行指令的模式: 内核模式(Kernel mode)和用户模式(user mode)。在内核模式中,处理器允许执行特权指令(privileged instructions),像读取和写入磁盘(或任何其他I/O设备)就是一个特权指令。如果用户模式下的应用程序尝试执行特权指令,但处理器不会执行该指令,而是切换到内核模式,以便内核模式下的软件可以清理应用程序,因为它执行了不应该执行的操作。第0章中的图0-1说明了这一组织操作系统 强隔离。应用程序只能执行用户模式指令(例如添加数字等),并且被认为是在用户空间中运行,而内核模式下的软件也可以执行特权指令,并被称为在内核空间中运行。在内核空间(或内核模式) 运行的软件称为内核。
如果用户模式应用程序必须读取或写入磁盘,则必须转换到内核才能执行此操作,因为应用程序本身无法执行I/O指令。处理器提供了一个特殊的指令,将处理器从用户模式切换到内核模式,并在内核指定的入口点进入内核。(x86处理器为此目的提供int指令。)一旦处理器切换到内核模式,内核就可以验证系统调用的参数,决定是否允许应用程序执行请求的操作,然后拒绝或执行它。由内核来设置转换到内核模式的入口点是非常重要的,如果应用程序可以决定内核入口点,则恶意应用程序可以在跳过参数验证的位置进入内核。
内核组织
操作系统的一个关键设计问题是操作系统的哪一部分应该在内核模式下运行。一个简单的答案是内核接口是系统调用接口。也就是说,fork exec open`closereadwrite`等都是内核调用。此选择意味着操作系统的完整实现在内核模式下运行。这种内核组织被称为单片内核(monolithic kernel)。
在此组织中,完整的操作系统以完全硬件权限运行。此组织很方便,因为操作系统设计者不必决定操作系统的哪一部分不需要完全的硬件特权。此外,操作系统的不同部分也很容易进行合作。例如,操作系统可以具有文件系统和虚拟内存系统可以共享的缓冲区缓存。
整体组织的一个缺点是,操作系统不同部分之间的接口通常很复杂(我们将在本文的其余部分看到),因此操作系统开发人员很容易犯错。在单片内核中,错误是致命的,因为内核模式中的错误通常会导致内核失败。如果内核出现故障,计算机将停止工作,因此所有应用程序也将失败。计算机必须重新启动才能重新启动。
为了降低内核出现错误的风险,操作系统设计人员可以将在内核模式下运行的代码行做得更小。大多数操作系统不需要访问到特权指令,从而可以作为普通的用户级应用程序运行,与应用程序通过消息进行交互。这个内核组织被称为微内核(microkernel)。
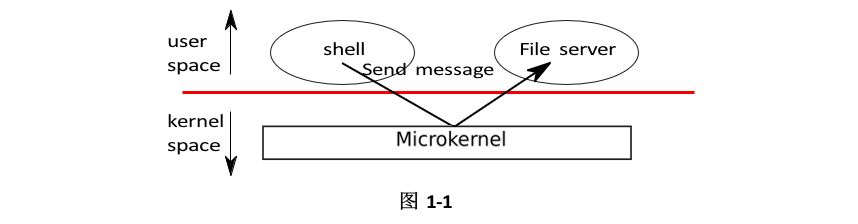 图1-1说明了这种微内核设计。在图中,文件系统作为用户级应用程序运行。为普通用户程序运行提供服务的操作系统称为服务器。为了允许应用程序与文件服务器交互,内核提供了一种最小的机制,用于将消息从一个用户模式应用程序发送到另一个用户模式应用程序。例如,如果像shell这样的应用程序想要读取或写入文件,它将向文件服务器发送一条消息并等待响应。
图1-1说明了这种微内核设计。在图中,文件系统作为用户级应用程序运行。为普通用户程序运行提供服务的操作系统称为服务器。为了允许应用程序与文件服务器交互,内核提供了一种最小的机制,用于将消息从一个用户模式应用程序发送到另一个用户模式应用程序。例如,如果像shell这样的应用程序想要读取或写入文件,它将向文件服务器发送一条消息并等待响应。
在微内核中,内核接口由一些用于启动应用程序、执行I/O、向应用程序发送消息这样低级函数组成。此组织允许使用几行代码实现内核,因为它没有做太多事情,因为操作系统的大多数功能都是由用户级服务器实现的。
在现实世界中,人们既可以找到单片内核,也可以找到微内核。例如,Linux 主要是作为一个单片内核实现的,尽管某些操作系统功能作为用户级服务器(例如,窗口系统) 运行。Xv6 是作为一个单片内核实现的,遵循大多数Unix操作系统。因此,在xv6中,内核接口对应于操作系统接口,内核实现完整的操作系统。由于xv6提供的功能不多,它的内核比一些微内核小。
下图是译者提供的内核结构图比较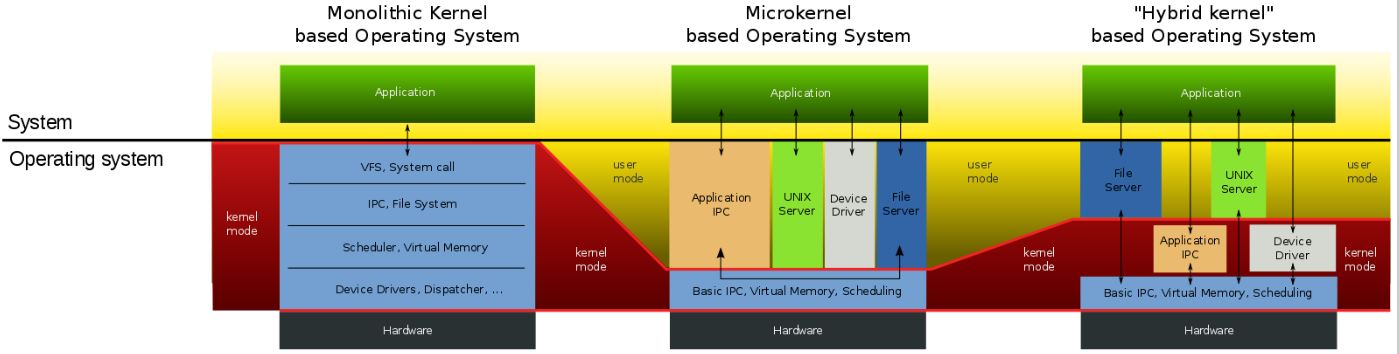
进程概述
xv6中的隔离单元(与其他Unix操作系统中一样)叫做进程。进程抽象可防止一个进程破坏或监视另一个进程的内存、CPU、文件描述符等。它还可以防止进程破坏内核本身(即阻止内核强制隔离)。内核必须谨慎地实现进程抽象,因为错误或恶意应用程序可能会欺骗内核或硬件做一些不好的事情(例如,绕过强制隔离)。内核用于实现进程的机制包括用户/内核模式标志、地址空间和线程的时间切片,本小节对此进行了概述。
为了能够强制隔离,一个过程是一个抽象,就好像一个程序拥有它有自己的抽象机器。进程提供给程序专有的内存系统,或地址空间,其他进程无法读取或写入。进程还给程序提供私有CPU执行程序指令的假象。
Xv6 使用页表(由硬件实现)为每个进程提供自己的地址空间。x86页表将虚拟地址(“地图”)转换为物理地址(处理器芯片发送到主内存的地址)
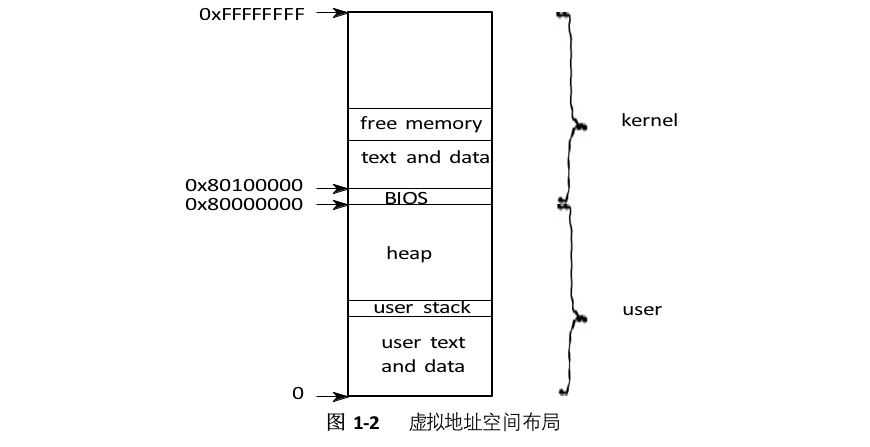 Xv6为每个进程维护一个单独的页面表,用于定义该进程的地址空间。如图1-2所示,地址空间包括从虚拟地址零开始的进程的用户内存。先是指令,然后是全局变量,然后是堆栈,最后是一个“堆”区域(用于malloc),进程可以根据需要扩展。
Xv6为每个进程维护一个单独的页面表,用于定义该进程的地址空间。如图1-2所示,地址空间包括从虚拟地址零开始的进程的用户内存。先是指令,然后是全局变量,然后是堆栈,最后是一个“堆”区域(用于malloc),进程可以根据需要扩展。
每个进程的地址空间映射内核的指令和数据以及用户程序的内存。当进程调用系统调用时,系统调用将在进程地址空间的内核映射中执行。这种安排的存在,以便内核的系统调用代码可以直接引用用户内存。为了给用户内存的增长留出空间,xv6的地址空间将内核映射到高地址,从0x80100000开始。
xv6内核为每个进程维护许多状态片段, 并将其收集到一个结构proc(第2353行)中。进程最重要的内核状态是它的页面表、内核堆栈和运行状态。我们将使用符号p->xxx来引用proc结构的元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//译者引入
//Per−process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non−zero, sleeping on chan
int killed; // If non−zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging) 2367 };
}
每个进程都有一个执行线程(或简称线程)来执行进程的指令。线程可以挂起,然后恢复。要在进程之间透明地切换,内核将挂起当前正在运行的线程,并恢复另一个进程的线程。线程的大部分状态(局部变量、函数调用返回地址)存储在线程的堆栈中。每个进程都有两个堆栈:用户栈和内核栈(p->kstack)。当进程执行用户指令时,只有其用户栈正在使用中,其内核栈为空。当进程进入内核(如系统调用或中断)时,内核代码将在进程的内核堆栈上执行;当进程在内核中时,其用户堆栈仍然包含已保存的数据,但未被积极使用。进程的线程在主动使用其用户堆栈和内核堆栈之间交替进行。内核堆栈是独立的(并与用户代码一起保护),因此即使进程破坏了其用户堆栈,内核也可以执行。
当进程进行系统调用时,处理器切换到内核堆栈,提高硬件权限级别,并开始执行实现系统调用的内核指令。系统调用完成后,内核将返回到用户空间:硬件降低其权限级别,切换回用户堆栈,并在系统调用指令之后继续执行用户指令。进程的线程可以在内核中阻塞去等待I/O,并在I/O完成后从停止的位置继续执行。
p->state指示进程是分配、准备运行、运行、等待I/O还是退出。
p->pgdir保存进程的页表,格式为x86硬件所期望的格式。xv6会导致分页硬件在执行进程时使用进程的p->pgdir。进程的页表还可作为分配给存储进程内存的物理页的地址的记录。
代码:第一个地址空间
为了使xv6的组织更加具体,我们将了解内核如何创建第一个地址空间(为其自身),如何创建并启动第一个进程,以及该进程进行的第一个系统调用。通过跟踪这些操作,我们详细了解xv6如何为进程提供强大的隔离。提供强隔离的第一步是将内核设置为在其自己的地址空间中运行。
当PC通电时,它会初始化自身,然后将引导加载程序(boot loader)从磁盘加载到内存中并执行它。附录B(MIT 6.828 book_xv6:Appendix B,译者注)解释了细节。Xv6的引导加载程序从磁盘加载xv6内核,并从entry(第1040行)开始执行它。内核启动时,未启用x86分页硬件;虚拟地址直接映射到物理地址。
1 | //译者引入 |
引导加载程序将xv6内核加载到物理地址0x100000的内存中。它不将内核加载到0x80100000(内核希望在那里找到它的指令和数据)的原因是,在一台小机器上,在这么高的地址可能没有任何物理内存。它之所以将内核放在0x100000而不是0x0, 是因为地址范围0xa0000: 0x100000包含I/O设备。
为了允许内核的其余部分运行,entrty设置一个页表, 将从0x800000开始的虚拟地址(称为KHRNBASE(第0207行))映射到0x0开始的物理地址(参见图 1-2)。设置两个映射到相同物理内存范围的虚拟地址范围是页表的常见用法,我们将看到更多类似这样的示例。
入口页表(entry page table)是在main. c(1311)中定义的。我们将在第2章中查看页表的详细信息,简短来说就是entry 0映射了虚拟地址0:0x400000到物理地址0:0x400000。只要entry在低地址执行,但最终都会被移除,那就需要此映射。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 译者引入
// Key addresses for address space layout (see kmap in vm.c for layout)
// Boot page table used in entry.S and entryother.S.
// Page directories (and page tables), must start on a page boundary,
// hence the "__aligned__" attribute.
// Use PTE_PS in page directory entry to enable 4Mbyte pages.
__attribute__((__aligned__(PGSIZE)))
pde_t entrypgdir[NPDENTRIES] = {
// Map VA’s [0, 4MB) to PA’s [0, 4MB)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// Map VA’s [KERNBASE, KERNBASE+4MB) to PA’s [0, 4MB)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,
};
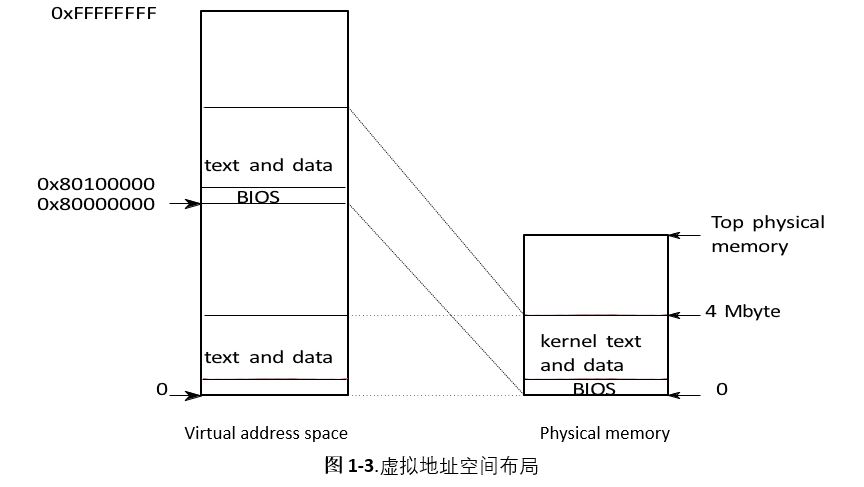
Entry 512将虚拟地址KERNBASE:KERNBASE+0x400000 映射到物理地址0:0x400000。此entry将在entry完成后由内核使用;它将内核希望找到其指令和数据的高虚拟地址映射到引导加载程序加载加载器加载它们的低物理地址。此映射将内核指令和数据限制为4Mb。
回到entry过程中,它将entrypgdir的物理地址加载到控制寄存器%cr3中。分页硬件必须知道entrypgdir的物理地址,因为它还不知道如何翻译虚拟地址,即它还没有一个页面表。符号entrypgdir指向高内存中的地址,宏V2P_WO(0220)减去KERNBASE以查找物理地址。若要启用分页硬件,xv6在控制寄存器%cr0中设置CR0_PG标志。
启用分页后,处理器仍在低地址执行指令,这是因为entrypgdir映射低地址。如果xv6省略了 entrypgdir中的entry 0,则启用分页之后去尝试执行指令时,计算机将崩溃。
现在,entry需要跳转到内核的C代码,并在高内存中运行它。首先,它使堆栈指针%esp 指向要用作堆栈(1054)的内存。所有符号都有较高的地址(包括堆栈),因此即使删除了低映射,堆栈依旧有效。最后,entry进入main,这也是一个高地址。间接跳转是必要的,因为汇编程序将生成一个相对于pc的直接跳转,这将执行内存不足版本的main。Main无法返回,因为堆栈上没有返回 PC。现在内核在函数main(1217)中的高地址运行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34//译者引入
# Set up the stack pointer.
movl $(stack + KSTACKSIZE), %esp
// Bootstrap processor starts running C code here.
// Allocate a real stack and switch to it, first
// doing some setup required for memory allocator to work.
int
main(void)
{
kinit1(end, P2V(4*1024*1024)); // phys page allocator
kvmalloc(); // kernel page table
mpinit(); // collect info about this machine
lapicinit(); 1223 seginit(); // set up segments
cprintf("\ncpu%d: starting xv6\n\n", cpu−>id);
picinit(); // interrupt controller
ioapicinit(); // another interrupt controller
consoleinit(); // I/O devices & their interrupts
uartinit(); // serial port
pinit(); // process table
tvinit(); // trap vectors
binit(); // buffer cache
fileinit(); // file table
iinit(); // inode cache
ideinit(); // disk
if(!ismp)
timerinit(); // uniprocessor timer
startothers(); // start other processors
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()
userinit(); // first user process 1240
// Finish setting up this processor in mpmain.
mpmain();
}
代码:创建第一个进程
现在内核在自己的地址空间内运行,我们来看看内核是如何创建用户级进程的,并确保内核和用户级进程之间以及进程本身之间的强隔离。
在main初始化多个设备和子系统后,它通过调用userinit(1239)创建第一个进程。Userinit 的第一个操作是调用allocproc。Allocproc(2455)的工作是在进程表中分配一个插槽0(槽就是一个proc结构体),并初始化内核线程执行所需的进程状态的各个部分。每个新进程都调用Allocproc,只有第一个进程调用userinit。Allocproc扫描proc表中是否有UNUSED状态的插槽(2461-2463)。当它找到未使用的插槽时,allocproc将状态设置为EMBMYO,将其标记为已使用,并为进程提供一个唯一的pid(2451-2469)。接下来,它尝试为进程的内核线程分配一个内核堆栈。如果内存分配失败,则allocproc会将状态更改回UNSED,并返回零信号失败。
1 | //译者引入 |
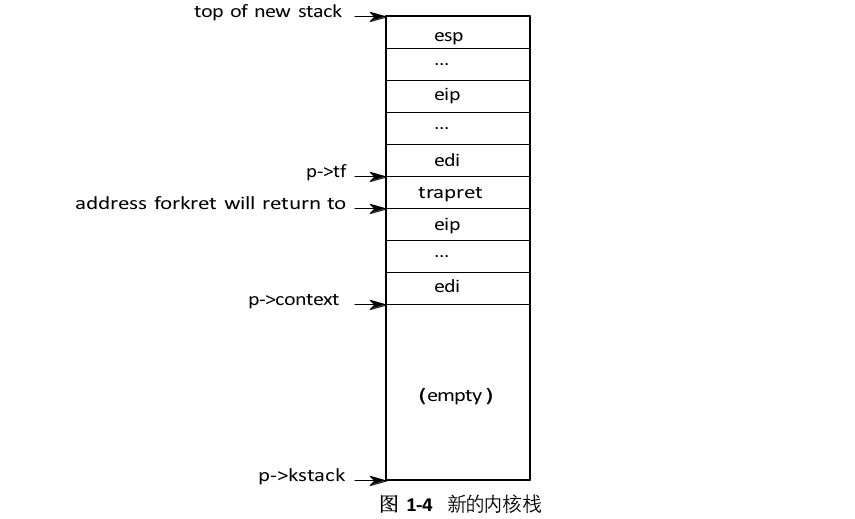
现在,allocproc必须设置新进程的内核堆栈。使用allocproc这个名词以便在创建第一个进程时可以使用fork。allocproc使用专门准备的内核堆栈和一组内核寄存器来设置新进程,这些内核寄存器集导致它在首次运行时“返回”到用户空间。准备好的内核堆栈的布局如图1-4所示。allocproc通过设置返回程序计数器值来完成这项工作的一部分,这将导致新进程的内核线程首先在forkret中执行,然后在trapret中执行(2486-2491)。内核线程将从p->context复制的寄存器内容开始执行。因此,将p->context->eip设置为forkret将导致内核线程在forkret(2783)开始时执行。此函数将返回到堆栈底部的任何地址。上下文切换代码(2958)将堆栈指针设置为p->context上方。allocproc把p->context放在栈上,并把指向trapret的指针放在上面,这就是forkret返回的地址。trapret从保存在内核栈的顶部的值恢复到用户寄存器上,并跳转到进程(3277)。此设置对于普通fork和创建第一个进程是相同的,尽管在后一种情况下,进程将开始在用户空间位置为零执行,而不是从fork返回的地方。
正如我们将在第3章中看到的,控制从用户软件传输到内核的方式是通过中断机制进行的,该机制由系统调用、中断和异常被使用。每当进程运行时控制传输到内核时,硬件和xv6陷阱输入代码将把用户寄存器保存在进程的内核堆栈上。userinit在新堆栈的顶部写入值,这些值看起来就像,如果进程是通过中断(2514-2520)进入内核的,就会一直在那里。因此从内核返回到进程的用户代码的二进制代码将工作。这些值存储着用户寄存器的struct trapframe。现在,新的进程的内核堆栈已完全准备好,如图1-4 所示。第一个进程将执行一个小程序(initcode.S;(8200))。进程需要物理内存来存储这个程序,该程序需要复制到内存中,并且该进程需要引用该内存的页表。
1 | //译者引入 |
userinit调用setupkvm(1837)为进程创建一个页表,其中(首先)只用于内核使用的内存。我们将在第2章中详细研究此函数,但在高级setupkvm和userinit中创建一个地址空间,如图1-2所示。
第一个进程内存的初始内容是initcode.S的编译形式;作为内核构建过程的一部分,链接器在内核中嵌入了二进制,并定义了两个特殊符号, _binary_initcode_start和_binary_initcode_size,指示二进制文件的位置和大小。Userinit通过调用inituvm将该二进制文件复制到新进程的内存中,其将分配物理内存的一页,将虚拟地址零映射到该内存,并将二进制文件复制到该页(1903)。
然后,userinit使用初始用户模式状态设置陷阱帧(0602):%cs寄存器包含在特权级别DPL_USER(如用户模式而非内核模式)上运行的SEG_UCODE段的段选择器,同样%ds、%es和%ss使用享有特权DPL_USER的SEG_UDATA。%eflags FL_IF 位设置为允许硬件中断;我们将在第3章中重新讨论这个问题。
堆栈指针%esp设置为进程的最大有效虚拟地址p->sz。指令指针设置为initcode的入口点,地址0。
函数userinit将p->name设置为initcode,主要用于调试。设置p->cwd为进程的当前工作目录;我们将在第6章中详细研究namei。
初始化进程后,userinit会通过将p->state设置为RUNNABLE来标记它可用于计划。
代码:运行第一个进程
现在,第一个进程的状态已准备好,是运行它的时候了。在main调用userinit之后,mpmain调用调度程序(scheduler)以启动运行进程(1267)。Scheduler(2708)查找将p->state设置为”RUNNABLE”的进程,并且只有一个进程:initproc。它将每个cpu变量proc设置为它找到的进程,并调用switchnum告诉硬件开始使用目标进程的页面表(1868)。在内核中执行更改页面表是有效的,因为setupkvm会导致所有进程的页面表对内核代码和数据具有相同的映射。Switchnvm还设置了一个任务状态段SEG_TSS指示硬件在进程的内核堆栈上执行系统调用和中断。我们将在第3章中重新检查任务状态段1
2
3
4
5
6
7
8
9
10
11
12//译者引入
//1260-1268
// Common CPU setup code.
static void
mpmain(void)
{
cprintf("cpu%d: starting\n", cpu−>id);
idtinit(); // load idt register
xchg(&cpu−>started, 1); // tell startothers() we’re up
scheduler(); // start running processes
}
Scheduler现在将p->state设置为RUNNING,并调用swtch(2958)执行对目标进程的内核线程的上下文切换。swtch 保存当前寄存器,并将目标内核线程(proc->context)保存的寄存器加载到x86硬件寄存器中,包括堆栈指针和指令指针。当前上下文不是一个进程,而是一个特殊的per-cpu scheduler上下文,因此scheduler告诉swtch将当前硬件寄存器保存在per-cpu存储(cpu-schedule)中,而不是保存在任何进程的内核线程上下文。我们将在第5章中详细介绍swtch。最后的ret指令(2977)从堆栈中弹出目标进程的%eip,完成上下文切换。现在处理器运行在进程p的内核栈中。
Allocproc设置initproc的p->context->eip为forkret,因此,ret从forkret开始执行。在第一次调用(即这一次)上,forkret(2783)运行无法在main运行的初始化函数,因为它们必须在具有自己的内核堆栈的常规进程的上下文中运行。然后,forkret返回。Allocproc安排,p->context弹出后堆栈上的顶部单词是trapret,因此现在trapret开始执行,%esp设置为p->tf。Trapret(3277)使用弹出指令从陷阱帧(0602,trap frame)恢复寄存器,就像swtch对内核上下文所做的那样:popal还原常规寄存器,然后popl指令还原%gs、%fs、%es和%ds。addl跳过两个字段trapno和errcode。最后,iret指令从堆栈弹出%cs、%eip、%flags、%esp和%ss。陷阱帧的内容已转移到CPU状态,因此处理器将继续在陷阱帧中指定的%eip。对于initproc,这意味着虚拟地址零,即initproc.S的第一个指令。
此时,%eip为零,%esp为4096。这些是进程地址空间中的虚拟地址。处理器的分页硬件将它们转换为物理地址。allocuvm设置进程的页面表,使虚拟地址零指向为此进程分配的物理内存,并设置一个标志(PTE_U),告诉分页硬件允许用户代码访问该内存。userinit(2514)将%cs的低位设置为CPL=3去运行进程的用户代码,这意味着用户代码只能使用PTE_U标记的页面,并且不能修改敏感硬件寄存器,如%cr3。因此,该过程仅限于使用自己的内存。
第一个系统调用:exec
现在我们已经看到了内核如何为进程提供强大的隔离,让我们看看用户级进程如何可以重新进入内核,请求它可以执行的服务。
initcode.S中的第一个操作的是调用exec系统调用。正如我们在第0章中看到的,exec用一个新的程序替换当前进程的内存和寄存器,但它使文件描述符、进程id和父进程保持不变。
initcode.S(8208)首先将三个值推入栈中:$argv、$init和$0,然后将%eax设置为SYS_exec,并执行int T_SYSCALL:它要求内核运行exec系统调用。如果一切顺利,exec永远不会返回:它开始运行由$init命名的程序,该程序是指向nul终止字符串/init(8221-8223)的指针。如果exec失败并返回,initcode循环调用exit系统调用,这绝对不应该返回 (8215-8219)。1
2
3
4
5
6
7
8
9
10
11
12
13//译者引入
//8221-8223
init:
.string "/init\0"
//8215-8219
exit:
movl $SYS_exit, %eax
int $T_SYSCALL
jmp exit
Exec系统调用的参数是$init和$argv。最后的零使得这个手写的系统调用看起来像普通的系统调用,我们将在第3章中看到。与以前一样,此设置避免了对第一个进程的特殊化(在本例中为其第一个系统调用),而是重用xv6必须提供标准操作的代码。
第2章将详细介绍exec的实现,但在较高的层次上,它将用从文件系统加载的/init二进制文件替换initcode。现在,initcode(8200)已经完成,该进程将替代其运行。Init(8310)根据需要创建一个新的控制台设备文件,然后将其作为文件描述符0、1和2打开。然后,它循环,启动控制台外壳,处理孤立的僵尸,直到shell退出,并重复。至此系统已经完成启动。
1 | // init: The initial user−level program |
真实世界
大多数操作系统都采用了进程这一概念,大多数进程看起来与xv6的相似。一个真正的操作系统会在常数时间内找到具有显式空闲列表的空间proc结构,而不是在分配器中的线性时间搜索;为了简单,xv6使用线性扫描(许多扫描中的第一个)。
xv6的地址空间布局存在无法使用超过2GB的物理RAM的缺陷。解决这个问题是可能的,尽管最好的计划是切换到具有64位地址的机器。
练习
在swtch设置断点。单步调试到forkret,然后使用gdb的finish进行trapret,然后stepi,直到你得到在虚拟地址为零的initcode
KERNBASE限制单个进程可以使用的内存量,这可能会在具有完整的4GB RAM 的计算机上引起干扰。提升KERNBASE是否允许进程使用更多内存?