本书完整讲解InnoDB存储引擎的体系结构和工作原理,并结合InnoDB得到源代码讲解了它的内部实现机制
任何时候Why比What重要,只有真正理解内部实现原理、体系结构,才能更好地使用,这才是人类正确思考问题的原则
体系结构
MySQL由后台进程以及一个共享内存区组成,是单进程多线程架构
- 数据库:物理操作系统文件或其他形式文件类型的集合,依照某种数据模型组织起来并存放于二级存储器中的数据集合
- 实例:数据库实例才是真正用于操作数据库文件,应用程序通过其和数据库打交道
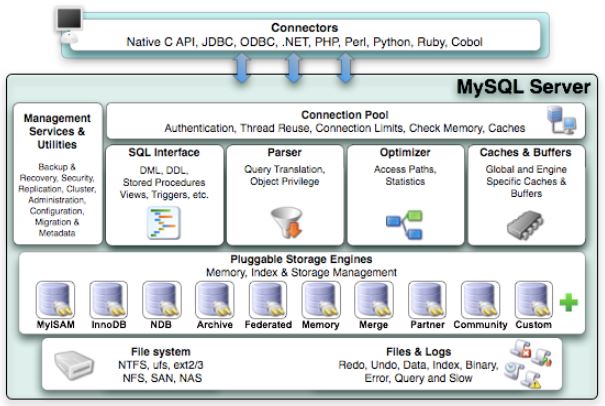 从上往下,从左往右依次是
从上往下,从左往右依次是 - 管理服务和工具组件
- 连接池组件
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲组件
- 插件式存储引擎:该特性是MySQL区别于其他数据库的重要特性;存储引擎是基于表的,而不是数据库;用户可以自由选择存储引擎,甚至修改引擎,使其符合自己的需求
- 物理文件
存储引擎之间还是有很大区别,要根据需要选择合适的引擎,有些引擎支持事务,有些则不支持
- InnoDB:支持事务、行锁设计、支持外检、非锁定读,多版本并发控制,实现了SQL标准的四种隔离级别,插入缓冲,二次写,自适应哈希索引,预读
- MyISAM:不支持事务(并不是所有应用都需要事务)、表锁设计,支持全文索引,缓冲池只缓冲索引文件,而不缓冲数据文件
连接数据库操作就是一个连接进程和MySQL数据库实例进行通信,本质上就是进程通信,常见的有管道、命名管道、命名子、TCP/IP、Unix域套接字等
源码结构
存储引擎的源码都在storage文件夹下,InnoDB的源码文件夹结构如下
- btr:B+树的实现
- buf:缓冲池的实现,包括LRU算法, FLUSH刷新算法
- dict:InnoDB中内存数据字典的实现
- dyn:InnoDB中动态数组的实现
- fil:InnoDB文件数据结构以及对文件的一些操作
- fsp:file space,对物理文件的管理,如页、区、段等
- ha:哈希算法的实现
- handler:插件式存储引起的实现
- ibuf:插入缓冲的实现
- include:头文件
- lock:如S锁、X锁的实现以及定义锁额度一系列算法
- log:日志缓冲和重组日志文件的实现
- mem:辅助缓冲池的实现,用来申请一些数据结构的内存
- mtr:事务的底层实现
- os:封装对OS的操作
- page:页的实现
- row:各种类型行数据的操作
- srv:参数的设计
- sync:互斥量的实现
- thr:封装的可移植的线程库
- trx:事务的实现
- ut:工具类