把内存管理交给虚拟机,但不可依赖于虚拟机的内存管理机制,这就是学习虚拟机的原因之一
- 内存划分
- 对象创建
- 对象内存布局
- 对象访问定位
Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,如下图,这些区域都有各自的用途。其中有些区域随着虚拟机进程的启动而存在,而有些区域则依赖用户线程的启动和结束而建立和销毁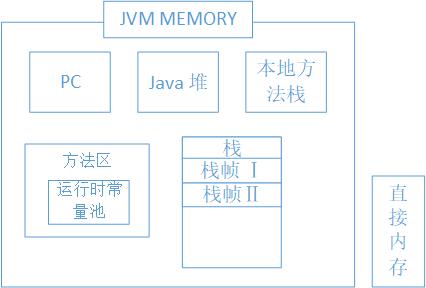
- 程序计数器(PC):和计组中的概念一样,都是存放程序,或者说是进程要执行的下一条字节指令,每个线程都有自己私有的程序计数器
- 栈:描述方法执行的内存模型,每个方法在执行的时候都会创建一个栈帧,用于存放局部变量表、操作数帧、动态链接、方法出口等信息,方法的开始结束对应于栈帧的入栈出栈
- 本地方法栈:和栈类似,不过对应的是native方法,即Java调用非Java代码的接口
- 堆:线程共享,所有对象和数组都要在堆上分配内存,堆是垃圾收集器作用的区域,因此成为GC堆
- 方法区:线程共享,存储已被虚拟机加载的类信息、常量、静态常量、JIT编译后的代码数据
- 运行时常量池:存放编译期产生的各种字面量和符号引用,在运行期间也能将常量放入池中
- 直接内存:可以使用native函数库直接在堆外分配内存,然后通过堆中的DirectByteBuffer对象引用这块内存
对象的内存布局分为对象头、实例数据和对齐填充三部分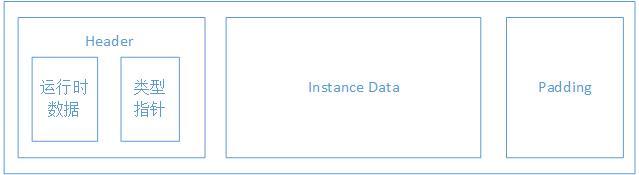
- 对象头:运行时数据指的就是GC分代年龄、HashCode、锁状态标志等数据,类型指针即对象指向它的类元数据的指针,通过这个指针来确定这个对象是哪个类的实例
- 实例数据:存储真正的有效信息,即程序代码中定义的各种类型的字段内容
- 对齐填充:自动内存管理系统要求对象的大小必须是8字节的整数倍,对象头固定是8字节的1倍或2倍,所有当实例数据部分没有对齐是,就需要对齐填充
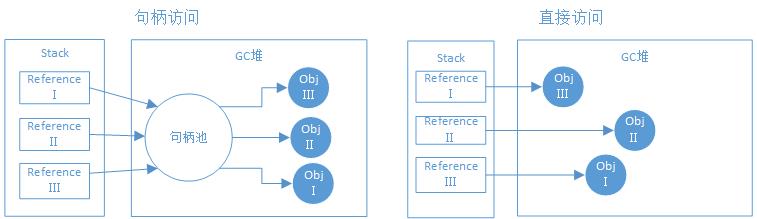
堆上的对象访问分为两种
- 句柄访问:在堆划分出一块句柄池,reference存储的就是对象的句柄地址,而句柄则保存对象实际的真实地址,这种方式的好处就是reference保存的是稳定的句柄地址,对象被移动时,只改变句柄中对应实例的数据指针
- 直接指针:reference直接保存对象的实际地址,好处就是速度快