网络应用中,进程、信号、字节顺序、内存映射以及动态内存分配都扮演重要角色。我们要理解基本的客户端-服务器编程模型,编写使用因特网提供的服务的客户端-服务器程序,最后将所有概念结合,开发一个虽小但功能齐全的Web服务器,为真实的Web浏览器提供静态和动态的文本和图形内容
网络模型
所有网络应用都基于相同的基本编程模型:客户端-服务器模型,有着相似的整体逻辑结构,并且依赖相同的编程接口
在这个模型中,一个应用是由一个服务器进程和多个客户端进程组成。服务器管理某种资源,并且通过操作这种资源为客户端提供某种服务。例如Web服务器管理一组磁盘文件,它代表客户端进程检索和执行;FTP服务器管理一组磁盘文件,它替客户端进行存储和检索;电子邮件服务器管理一些文件,它替客户端进行读和更新
认识到客户端和服务器是进程,而不是主机。一台主机可以同时运行不同的客户端和服务器。无论客户端和服务器怎么映射到主机上,该网络模型都是不变的
网络
网络是很复杂的系统,这里只学习皮毛
对主机而言,网络只是有一种I/O设备。从网络上接受到的数据从适配器经过I/O和内存总线复制到内存
以太网
从物理上将,网络是一个按照地理远近组成的层次系统。最低层是局域网(Local Area Network,LAN),最流行的局域网技术是以太网
一个以太网段包括一些电缆和一个集线器,常跨越小的区域,如一个楼层、一栋建筑等。电缆的一端连接主机的适配器,另一端连接集线器的端口。集线器不加分别的将一个端口上收到的每个位复制到所有端口,因此每个主机都能看到每个位
每个以太网适配器都有一个全球唯一的48位地址。主机发送帧到这个网段的任何主机,每个帧包含一些头部位,标志帧的源和目的地址以及帧的长度,随后就是数据位的有效载荷,每个主机适配器都能看到这个帧,但只有目的主机实际读取
利用电缆和网桥,多个以太网段可以组成更大的局域网,称为桥接以太网
互联网络
在层次更高级别中,多个不兼容的局域网可以通过路由器的特殊计算机连接起来,组成internet。由此连接起来的成为广域网(WAN)
互联网络至关重要的特性是,他能由采取不同和不兼容技术的各种局域网和广域网组成。每台主机和其他主机都是物理相连,如何能够让某台源主机跨过所有不兼容的网络发送数据到目的主机呢?
解决办法就是一层运行在主机和路由器上的协议软件。这种软件实现一种协议,这种协议控制主机和路由器如何协同工作来实现数据传输,这种协议必须提供两种基本能力:
- 命名机制:不同的局域网采取不同和不兼容的方式来为主机分配地址,互联网络通过定义一致的主机地址格式来消除差异。每台主机分配至少一个互联网络地址来标记自己
- 传送机制:互联网络通过定义一种把数据位捆扎成不连续的包的方式,消除差异,一个包由包头和有效载荷组成,其中包头包含包的大小和源主机以及目的主机的地址
具体流程参考,互联网思想的精髓就是封装
IP因特网
每个因特网主机都运行实现TCP/IP协议的软件。因特网的客户端和服务器混合使用套接字接口函数和Unix I/O函数来进行通信,通常套接字函数实现为系统调用,这些系统调用会陷入内核,并调用各种内核模式的TCP/IP函数
TCP/IP实际是一个协议族。IP协议提供基本的命名方式和递送机制,这种递送机制能够从一台因特网主机往其他主机发送数据报,但不是可靠地。UDP则稍微扩展了IP协议,这样数据报可以在进程间而不是主机间传送。TCP则是构建在IP之上的复杂协议,提供了进程间可靠地全双工连接
IP地址
IP地址就是一个32位无符号整数,但却放在一个结构中,因为这是套接字接口早期实现的不幸产物
主机可以有不同的主机字节顺序,TCP/IP为任意整数数据项定义了统一的网络字节顺序(大端字节顺序),即使主机字节顺序是小端法。Unix提供了载网络和主机字节顺序间转换的函数
IP地址使用一种点分十进制的表示法来表示,Unix提供了IP地址和点分十进制之间转换的函数
域名
因特网提供一组人性化的域名,以及一种将域名映射到IP的机制。这个映射是通过分布世界范围内的数据库(DNS)维护的,可以使用NSLOOKUP来查看,具体参见
因特网连接
一个套接字是连接的断点,每个套接字都有相应的套接字地址,由一个因特网地址和一个16位的整数端口组成
当客户端发起一个连接请求,客户端套接字地址中的端口是由内核自动分配的,然后服务器的端口通常是某个知名端口,是和这个服务相对应的,例如web服务器通常的端口是80。/etc/services包含了一张这台机器提供的知名服务和端口之间的映射
一个连接由两端的套接字地址唯一确定,称为套接字对
套接字接口
套接字接口是一组函数,与Unix I/O函数结合起来,用于创建网络应用
下图是典型的客户端-服务器事务的上下文中的套接字接口概述
从Linux内核的角度来看,一个套接字就是通信的一个端点,从Linux程序的角度来看,套接字就是由相应描述符的打开文件
socket
服务器和客户端使用该函数创建一个套接字描述符,如下1
clientfd = socket(AF_INEF,SOCK_STREAM,0);
AF_INEF表示使用的是32位地址,SOCK_STREAM表示这个套接字是连接的一个端点。socket返回的clientfd描述符是部分打开的,不能用于读写,如果完成打开套接字的工作,取决于是客户端还是服务器
connect
客户端通过调用connect函数来建立和服务器的连接1
2int connect(int clientfd,const struct sockaddr *addr,
socklen_t addrlen);
该函数会阻塞,一直到连接成功建立或者发生错误,如果成功,clientfd描述符就准备好读写了
bind
剩下的套接字函数(bind、listen、accept),都是服务器用来和客户端建立连接1
2int bind(int sockfd,const struct sockaddr *addr,
socklen_t addrlen);
该函数告诉内核将addr中的服务器套接字地址和套接字描述符sockfd联系起来
listen
默认情况下,内核认为socket函数创建的描述符对应于主动套接字,它存在于一个连接的客户端,服务器调用listen函数告诉内核,描述符是被服务器而不是客户端使用1
int listen(int sockfd,int backlog);
该函数将sockfd从一个主动套接字转化为一个监听套接字,该套接字接受来自客户端的连接请求。backlog参数暗示内核开始拒绝连接请求之前,队列中要排队的未完成的连接请求的数量
accept
服务器调用该函数来等待来自客户端的连接请求
1 | int accept(int listenfd,struct sockaddr *addr, |
该函数等待来自客户端的连接请求到达侦听描述符listenfd,然后在addr中填写客户端的套接字地址,并返回一个已连接描述符,该描述符可以利用Unix I/O函数与客户端通信
监听描述符和已连接描述符的区别:
- 监听描述符是作为客户端连接请求的一个端点,被创建一次,存在于服务器的整个生命周期
- 已连接描述符是客户端和服务器之间已经建立起来的连接的一个端点
- 区别这两种描述符是为了建立并发服务器,能够同时处理多个客户端连接
getaddrinfo
该函数将主机名、主机地址、服务名和端口号的字符串转化为套接字地址结构
1 | int getaddrinfo(const char *host,const char *service, |
规定host和service,该函数返回result,result是指向addrinfo结构的链表
客户端调用该函数之后,会遍历这个列表,依次尝试每个套接字地址,直到调用socket和connect成功,建立起连接。类似的,服务器也会尝试遍历列表的每个套接字地址,知道socket和bind成功,描述符会被绑定到一个合法的套接字地址
具体参数解释和链接结构参见书本P657-658
getnameinfo
该函数作用和getaddrinfo相反,将一个套接字地址结构转换成相应的主机和服务名字符串1
2
3int getnameinfo(const struct sockaddr *sa,socklen_t salen,
char *host,size_t hostlen,
char *service,size_t servlen,int flags);
下面的函数都是对上面的函数的封装
open_clientfd
客户端调用该函数建立与服务器的连接,服务器运行在主机hostname上,并在port端口号上监听连接请求,他返回一个打开的套接字描述符1
int open_clientfd(char *hostname,char *port);
open_listenfd
服务器调用该函数,创建一个监听描述符,准备好接受连接请求
Web服务器
HTTP是基于在因特网连接上传送的文本行的,可以使用linux上的TELNET程序来和因特网上的任何web服务器执行事务
具体细节参考其他文章
服务动态内容
这一需求引申出了很多问题:
- 客户端如何将程序参数传递给服务器?
- 服务器如何将这些参数传递给它所创建的子进程?
- 服务器如何将子进程生成内容所需要的其他信息传递给子进程?
- 子进程将输出结果发送到哪里?
上述问题都可以通过CGI(Common Gateway Interface,通用网关接口)的标准来解决
服务器在接收到一个请求后,如GET /cgi-bin/adder?15000&213 HTTP/1.1,它调用fork来创建子进程,并调用execve在子进程的上下文中执行/cgi-bin/adder程序,像这样的程序,常常被称为CGI程序,因为它遵守CGI标准的规则
在调用execve之前,子进程将CGI环境变量QUERY_STRING设置为”15000&213”,adder程序在运行时可以用linux getenv函数来引用它
CGI定义了大量的环境变量,一个CGI程序可以在运行时设置或使用这些变量
- SERVER_PORT:父进程侦听的端口
- REQUEST_METHOD:GET或POST
- REMOTE_HOST:客户端的域名
- …
一个CGI程序将它的动态内容发送到标准输出,在子进程加载并运行CGI程序之前,它使用dup函数将标准输出重定向到和客户端相关联的已连接描述符,因此CGI写入标准输出的东西就会直接到达客户端
因为父进程不知道子进程生成的内容和类型或者大小,所有进程要负责生成Content-type和Content-length响应报头,以及终止报头的空行
综合
接下来要开发称为TINY的服务器,在短短250行代码中,它结合了例如进程控制、Unix I/O、套接字接口和HTTP,虽然缺乏实际服务器具备的功能性、健壮性和安全性,但是当使用实际浏览器指向自己的服务器,依旧足够令人兴奋!!!
main
TINY是一个迭代服务器,监听在命令行传递来的端口上的连接请求
在调用open_listenfd函数打开一个监听套接字之后,就执行无限服务器循环,不断接受连接请求
doit
该函数处理HTTP事务
TINY只支持GET方法,如果客户请求其他方法,将发送错误信息,并返回到主程序,主程序随后关闭连接并等待下一个连接请求
然后我们将URI解析为一个文件名和一个可能为空的CGI参数字符串,并设置一个标志,表明请求时静态内容还是动态内容,如果文件在磁盘不存在,立即发送一个错误信息给客户端并返回
最后,如果请求的是静态内容,就验证该文件是普通文件,而我们有读权限,如果是这样就向客户端提供静态内容,如果请求的是动态内容,就验证文件是可执行文件,如果是这样就提供动态内容
clienterror
Tiny会检查一些明显的错误,并报告给客户端
该函数会发送一个HTTP响应给客户端,在响应行中包含相应的状态码和状态信息,相应主题包含一个HTML文件,向浏览器的用户解释这个信息。HTML响应中还应该指明主体内容的大小和类型
read_requesthdrs
TINY不使用请求报头的任何信息,仅仅调用该函数来读取并忽略这些报头
parse_uri
TINY假设静态内容的主目录就是当前目录,而可执行文件的目录是./cgi-bin,任何包含字符串cgi-bin的URI都被认为表示的是对动态内容的请求,默认的文件名是./home.html
serve_static
TINY提供五种常见类型的静态内容:HTML、无格式文本文件、GIF、PNG和JPG
该函数发送一个HTTP相应,其主体包含一个本地文件的内容。首先通过检查文件的后缀来判断文件类型,并且发送响应行和响应报头给客户端
接着,我们将被请求文件的内容复制到已连接描述符来发送响应主题。这里,需要仔细研究。首先open函数以只读方式打开文件,并获得描述符,再使用mmap函数将被请求文件映射到一个虚拟内存空间(该函数在第九章讲解)
一旦文件映射到内存,就不再需要他的描述符,而是需要文件开始的地址。最后调用函数从该地址开始复制filesize个字节到客户端的已连接描述符,最后释放映射的虚拟内存区域,避免潜在的致命的内存泄漏
serve_dynamic
TINY通过派生一子进程上的上下文来运行CGI程序
子进程重定向它的标准输出到已连接文件描述符,并加载运行CGI程序。因为CGI运行在子进程的上下文中,它能够访问所有在调用execve函数之前就存在的打开文件和环境变量,因此CGI写到标准输出的东西都将直接送到客户端进程,不会受到任何来自父进程的干涉。期间,父进程阻塞,等待子进程终止,回收子进程的资源
运行
网上的教程连编译命令都是错的,害人!
将tiny.c csapp.h csapp.c放在同一个文件夹下面,并创建home.html
编译xzy@ubuntu:gcc tiny.c -lpthread,然后运行xzy@ubuntu:./a.out 1024
如上所示,默认界面就是home.html
命令行中输出HTTP请求报文头
访问不存在的资源
使用telnet获取数据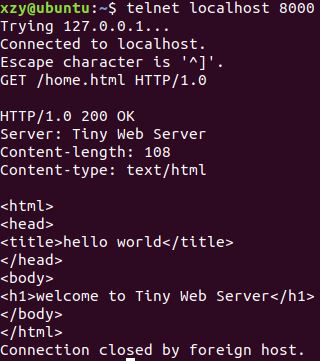
使用不支持的HTTP请求获取数据