简介
Web代理是在Web浏览器和终端服务器之间充当中间人的程序。浏览器不会直接联系最终服务器以获取网页,而是与代理联系,代理将请求转发到最终服务器。当终端服务器答复代理时,代理会将答复发送到浏览器
代理的作用:
- 在防火墙中使用代理,因此防火墙后面的浏览器只能通过代理与防火墙以外的服务器联系。
- 充当匿名者,通过剥离对所有标识信息的请求,代理可以使浏览器匿名到Web服务器
- 可以用于缓存web对象,方法是存储服务器中对象的本地副本,然后通过从缓存中读取对象 (而不是与远程服务器再次通信) 来响应将来的请求
这次的作业主要分三个部分
- Sequential Proxy: 接收客户端发送的HTTP请求,解析之后向目标服务器转发,获得响应之后再转发回客户端
- Concurrent Proxy: 在第一步的基础上,支持多线程
- Cache Web Objects: 使用LRU缓存单独的对象,而不是整个页面
先复习一下HTTP报文的格式
Part I
请求的header一定要有的内容是:
Host: 如Host: www.cmu.eduUser-Agent: 如User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3Connection: 如Connection: closeProxy-Connection: 如Proxy-Connection: close
代码倒是很快写好,问题出在了如何去调试上面,发现指针部分还是不熟练啊!1
2int conn_server(char *hostname,int *port,char *query_path);
int parse_url(char *url, char *hostname,char *query_path,int *port);
主要就是完成上面两个函数
这个实验倒是提升了自己的GDB的调试能力和对套接字接口的理解
Part II
在第十二章:并发编程提到了三种方式实现并发服务器,作为参考
采取生产者-消费者模型,并使用信号量,前面的章节掌握的好,在Part I的基础上修改成并发服务器并不难 可以发现实现并发之后,打开速度明显提快
可以发现实现并发之后,打开速度明显提快
Part III
HTTP实际上定义了一个相当复杂的模型,通过该模型,web服务器可以指示如何缓存它们所服务的对象,客户端可以指定如何代表它们使用缓存,而我们只需要实现简化版
此可能会出现一个巨型对象将消耗整个缓存的情况,从而防止缓存其他对象。为了避免这些问题,要设置maximum cache size maximum cache object size
对缓存的访问必须是线程安全的,确保缓存访问没有竞争条件可能是这个Lab更有趣的方面。事实上,有一个特殊的要求,即多个线程必须能够同时从缓存中读取。当然,一次只允许一个线程写入缓存,但读者必须不存在这种限制。因此,使用一个大型独占锁保护对缓存的访问不是一个可接受的解决方案。您可能需要探索一些选项,例如对缓存进行分区、使用Pthreads readers-writers locks或使用信号量来实现您自己的readers-writers解决方案。无论哪种情况,您不必实施严格的LRU eviction policy这一事实都会使您在支持多个读取器方面有一定的灵活性
写代码花了半天,调BUG花了一天,兜兜转转终于写出个能跑的代理服务器,虽然还是有很多BUG存在。调试BUG期间也是相当痛苦,尤其是在多线程的环境下,总感觉有股不自信在,或许是因为第一次接触,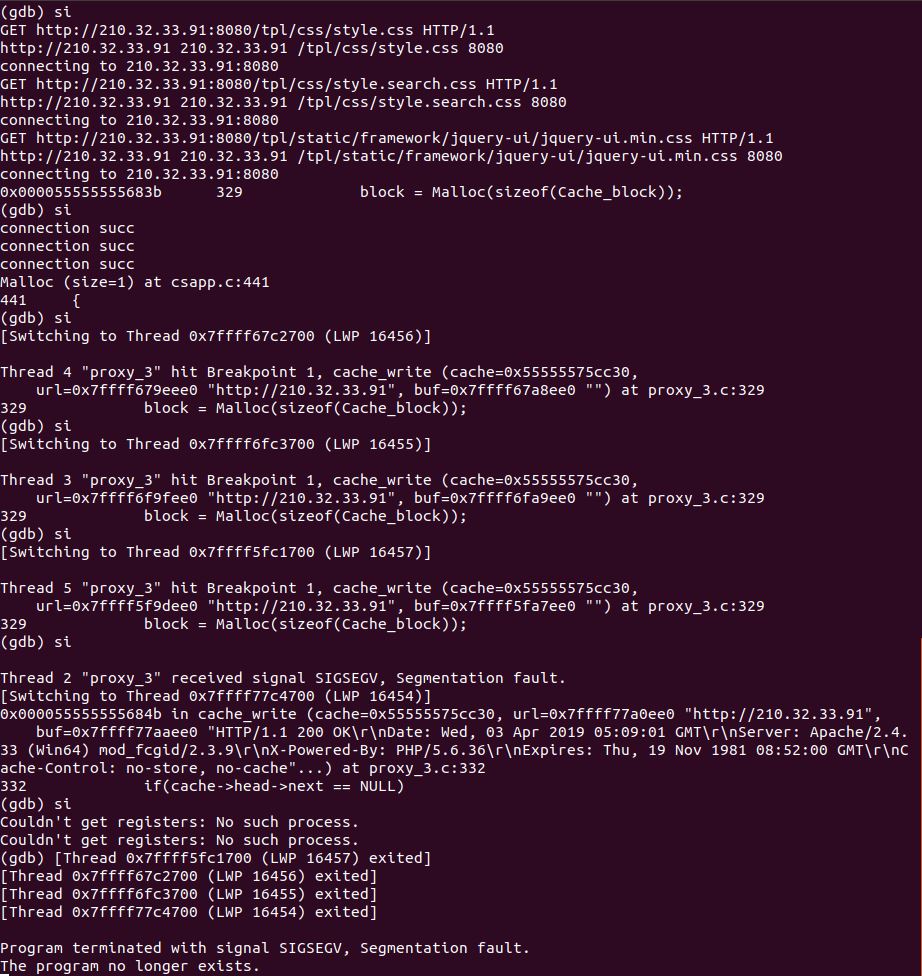
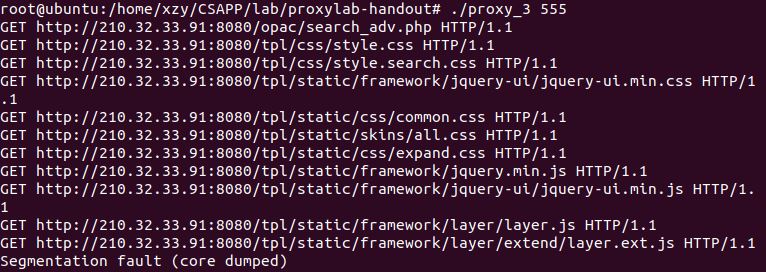

虽然整个循环已经建立,也就说能写入缓存,也能从缓存获取,但是依旧有一些BUG存在,之后会不断完善
完成这个实验,其实不要对多线程感到恐惧,并没有那么神秘,心态放端正